Lakehouse workflow
-
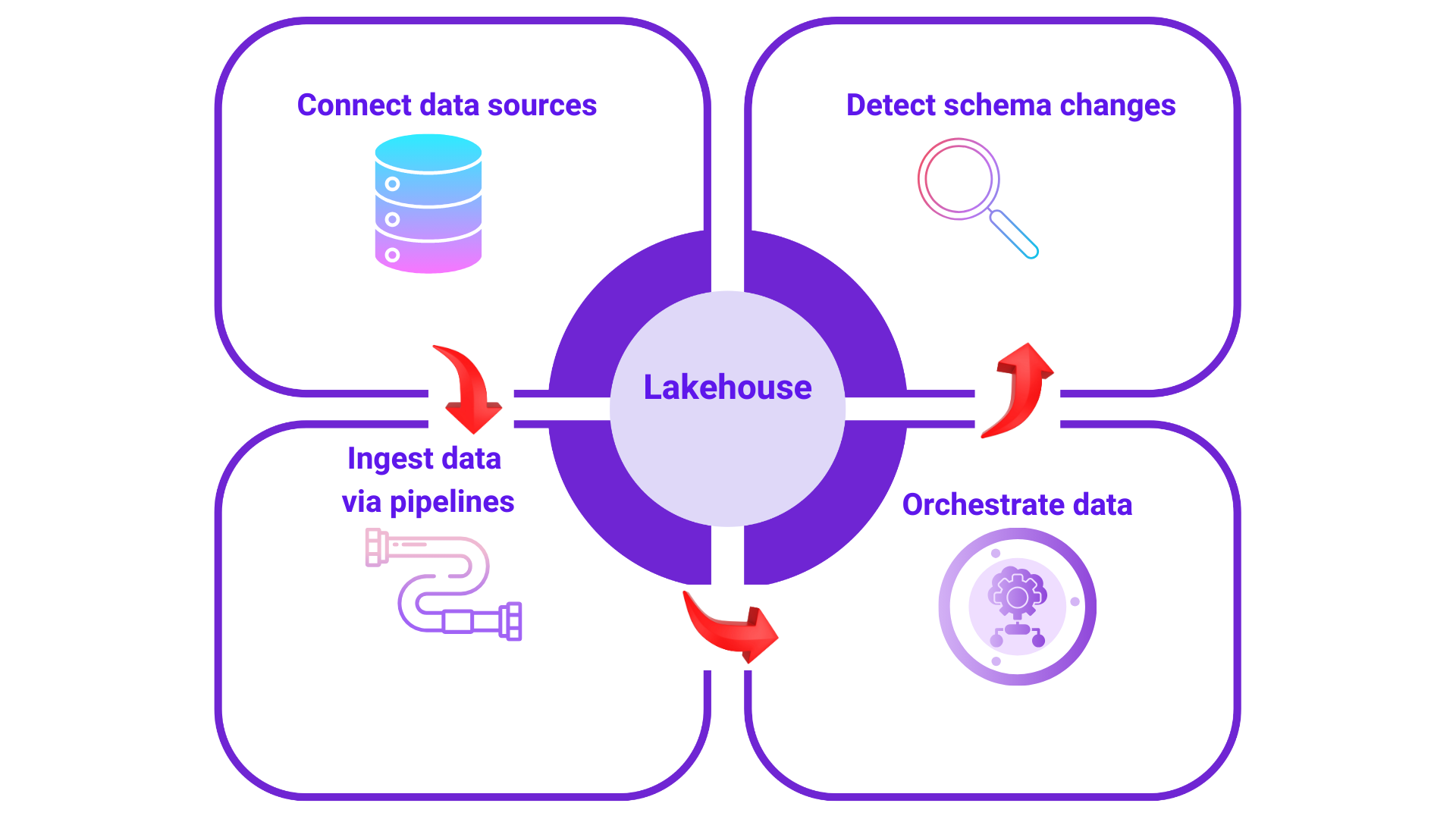
Connecting to data Sources: The journey begins with establishing connections to various data sources. Think of these as the starting points where your raw data lives. These could be relational databases like SQL Server, PostgreSQL, cloud data warehouses like Redshift, or even file storage systems such as S3 or Azure blob.. The crucial function here is to enable the Lakehouse to access the data that needs to be processed and analyzed.
-
Data ingestion via pipelines: Once the connections are in place, pipelines come into operation. Data ingestion is done via pipelines. Pipelines can get data from REST sources like Salesforce and Hubspot or JIRA or SQL sources like MS SQL, MYSQL or PostgreSQL databases.
Depending on the data source, it can fetch data in various modes. Currently supported modes are Full Refresh, Incremental, Incremental Append only,
The warehouse supports different file formats like parquet and iceberg.
-
Managing dependencies with orchestration: When dealing with multiple pipelines that need to run in a specific order or have dependencies on each other, orchestration becomes essential. Imagine a scenario where you need to process customer data before analyzing their purchase history. Orchestration tools allow you to define this logical flow, ensuring that pipelines execute in the correct sequence and that the entire data processing journey runs smoothly. It manages the "when" and "how" of pipeline execution.
-
Pipeline job monitoring: The Jobs section provides a centralized view of all pipeline executions, displaying upcoming scheduled jobs alongside currently running and any failed instances based on your selected filters. This allows for comprehensive monitoring of your data pipeline activities.
-
Continuous monitoring with schema change detection: Running in the background is the schema change detection mechanism. This constantly monitors the structure of the data in the original data sources. If any changes occur at the source level – for example, a new column is added, a data type is modified, or a table is altered – the schema change detection identifies these modifications. This is crucial for maintaining the integrity and consistency of the data within the Lakehouse. This is useful to understand the impacted pipelines and visualizations.
-
Responding to schema changes: When schema changes are detected, the system can alert data engineers or trigger automated processes to handle these changes within the Lakehouse. This might involve updating the data models, modifying existing pipelines, or even creating new ones to accommodate the altered data structure. The goal is to ensure that the Lakehouse remains synchronized with the source data and that downstream analytics and reporting are not negatively impacted by these changes.
In essence, the Lakehouse enables a continuous cycle: connect to data, ingest it through pipelines, orchestrate the flow, and constantly monitor for changes at the source to maintain a reliable and up-to-date data environment for analysis and decision-making.
Was this helpful?