DataGOL best practices
This document outlines DataGOL's recommended best practices, offering guidance, cautions, and solutions for various scenarios.
Lakehouse
Data source configuration
Whenever feasible, configure each data source with a unique user/password pair tailored to its specific purpose. This helps manage resources better and avoids duplication.
Naming convention for data sources
Names must be self-descriptive and follow a standardized format. Following are examples of a well-defined warehouse name:
- app_test_wh
- app: Represents the application data source.
- test: Indicates the environment or specific purpose.
- wh: Differentiates warehouses from data sources
- app_prod_db
- app: Represents the application data source.
- prod: Indicates the environment or specific purpose.
- db: Differentiates warehouses from warehouses
Naming convention for warehouses
When creating a new warehouse during the pipeline creation process, it's best practice to give it a self-descriptive name. A recommended approach is to preface the warehouse name with the name of the data source feeding the pipeline. For example: source - app_prod_db; warehouse - app_prod_wh
The suffix for the environment can also be added. For example: prod, staging, test, dev. Descriptions can also be added to the warehouse upon creation.
Data sources
Third party connectors
Please contact us via Slack to get your connectors whitelisted. This is a prerequisite to add any third party connector such as PostHog, Hubspot, SFTP Bulk etc from the data source page.
What to do?
To query data from a third-party connector in DataGOL, you must create a pipeline to move that data into your warehouse. Only then will the data be queryable.
Key steps
- Create a Standard pipeline with source as the REST connector and destination as warehouse.
- Select the required streams you want to ingest.
- Configure sync modes for each stream—Incremental Append is the recommended option for REST APIs. Most suitable cursor field (for example: updated_at, created_at) will be automatically captured based on your data to track changes efficiently.
REST APIs commonly transmit updated records as separate, new entries. Consequently, a deduplication pipeline will probably be necessary further down your data flow to eliminate duplicates and ensure you retain only the most current version of each record.
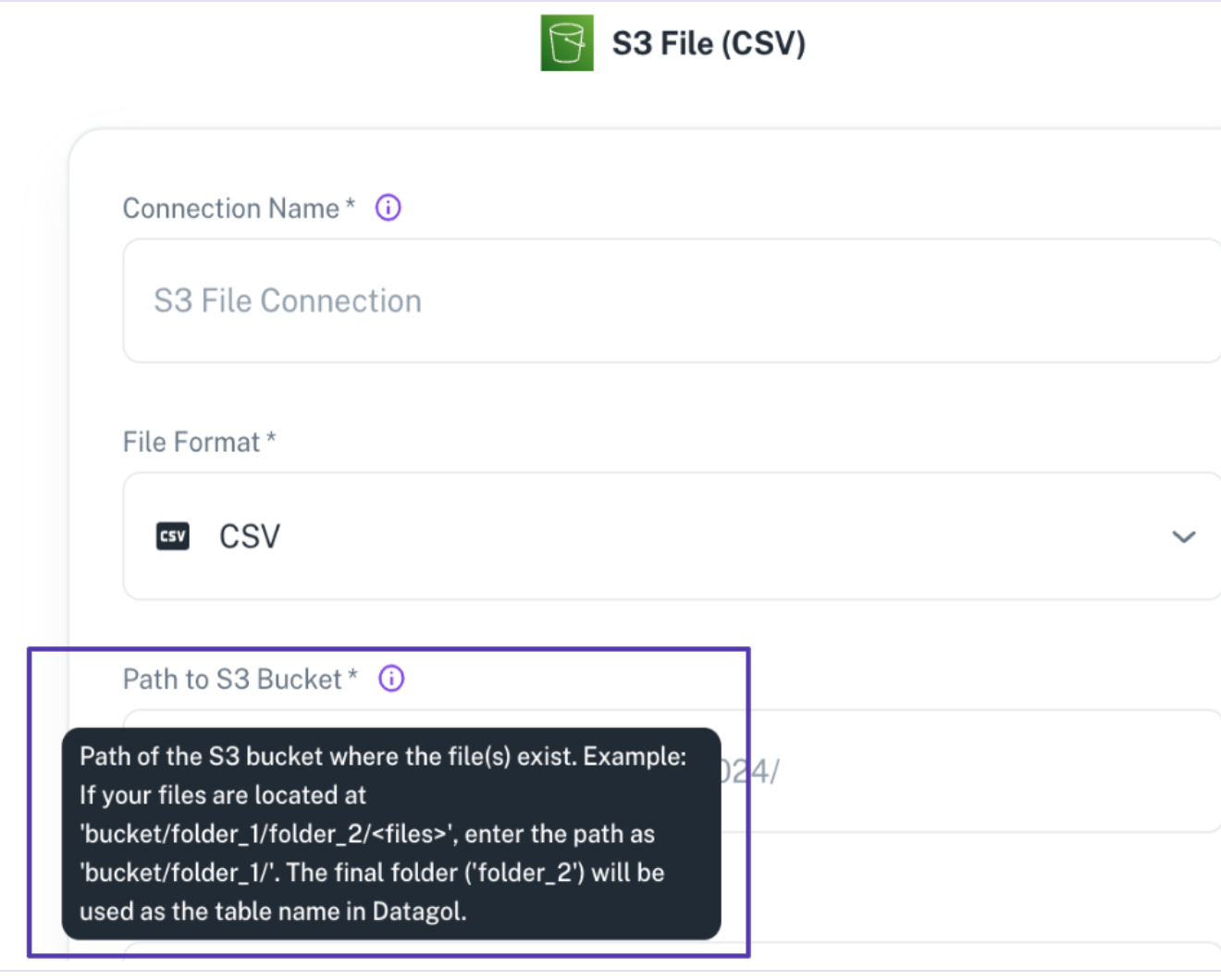
S3 as data source
When adding a S3 as a data source in DataGOL, ensure to provide the correct path structure to ensure proper ingestion.
Path Format:
If your files are stored at:
bucket/folder_1/table_name/<files>
Then you should specify the path to share as:
bucket/folder_1/
In this case, table_name (folder) will be treated as the table name. All files inside table_name` will be appended together based on a common schema.
Make sure that the files within the folder have a consistent schema to avoid ingestion issues.
Folder as data source
When a folder data source is created, each folder within it is treated as a separate table. Therefore, it is recommended to provide meaningful and descriptive names to the folders.
Ensure to note the following:
-
All files within a folder should have the same schema.
-
Ensure that the data types of corresponding columns are consistent across all files.
-
If there are inconsistencies, the data types from the most recently added file will take precedence.
Same warehouse but multiple sources
The Bronze Layer is where raw data is first ingested directly from source systems. Its purpose is to capture this data in its most unaltered and granular form. It's essential to ensure a clean and efficient landing at this stage, as any data quality issues will inevitably cascade through all downstream layers and pipelines. Therefore, the focus of the Bronze Layer is entirely on optimizing the cleanliness and efficiency of data ingestion.
- Scenario: Multiple data sources are syncing data into the same warehouse via pipeline.
- Risk: Data can get overwritten, leading to confusion and data integrity issues.
- Solution: Dedicated Warehouse for each source. Hence, refrain from using the same warehouse for syncing data from different sources unless those sources contain unique tables. Each warehouse must maintain a unique set of tables.
- Standardize Naming Conventions: In case of custom pipelines, prefix output table names with the source name (For example: salesforce_contacts, hubspot_contacts) to prevent overwrites.
Schema change impacts
- Scenario: Schema change in source after view and widgets are created.
- Impact: If a column used in a view is renamed, removed, or updated which is not consistent with its previous state in the source db, all downstream pipelines (For example: materialized views) and any widgets or dashboards relying on that column will break or fail to load properly.
- Solution: To handle schema changes, it's crucial to update all affected views and dashboards to reflect new column names, or data types. Impact Analysis can easily identify these changes, providing an overview of all modules that will be affected. Furthermore, if the modified column is utilized in downstream pipelines (For example: dedupe pipelines), associated queries must be reviewed and updated to ensure continued functionality and data integrity.
Sync Schema Failure
- Scenario 1: Tables not syncing and displaying "0" after adding a data source.
- Scenario 2: Manual
Sync Schematriggers fail to complete, and the last sync date remains unchanged. - Solution: Contact us via Slack
Data types changes
- Scenario: A column's data type is assigned incorrectly or later changed (For example: from string to integer or date to timestamp) after views, dashboards, or downstream pipelines have been built.
- Impact:
- Data can become corrupted or misrepresented (For example: truncation, nulls, or incorrect values).
- Warehouse queries may fail due to type mismatch errors.
- BI dashboards and widgets relying on the original data type can break silently or return incorrect results.
- Leads to significant rework across views, pipelines, and reporting layers.
- Solution:
- Be intentional when assigning data types—choose the most appropriate type for long-term use.
- Identify and review all dependent views, queries, and dashboards.
- Use Playground to update the datatypes of the column before publishing as a workbook.
- Make sure to keep the datatypes in the workbook consistent to its usage in BI.
- Update downstream pipeline queries to match the new data type.
- Communicate changes clearly with all users in the workspace to avoid unnoticed breakages of widgets in dashboards.
Recommended warehouse count
While there's no strict limit on the number of warehouses you can create, it's considered best practice to set up a separate warehouse for each independent data source. This approach helps prevent duplicate tables from being pushed into the same warehouse and ensures better data organization.
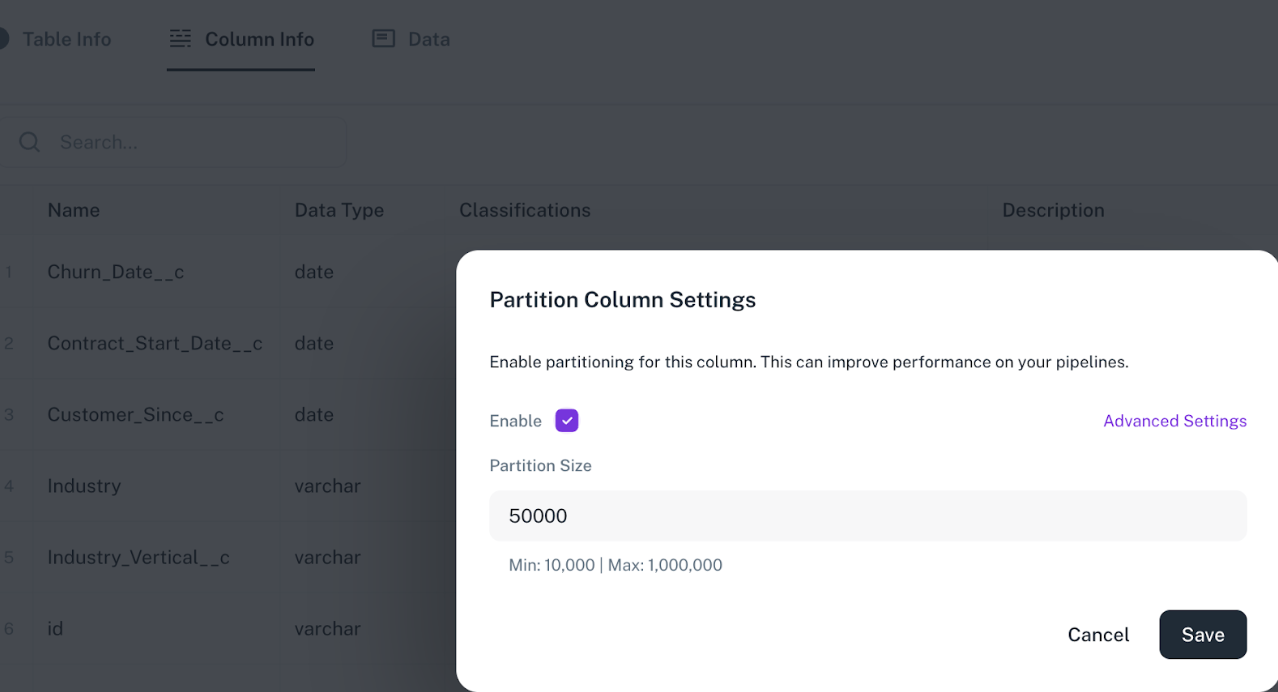
Partition column usage (when the data size is large)
Adding a partition column to your data source is highly beneficial when the data source has millions of records. In such cases, when a pipeline is created on a data source with a partition column, it enables the generation of multiple parallel tasks. This facilitates efficient data transfer to the warehouse and helps prevent connection timeout issues. The default partition size is 50,000 while the user has the flexibility to change it between 10,000 and 1,000,000 within the additional settings.
- Implication The Partition Column is not supported for warehouses.
- Steps: Lakeshouse > Data Sources > Table > Column Info > Make Partition Column
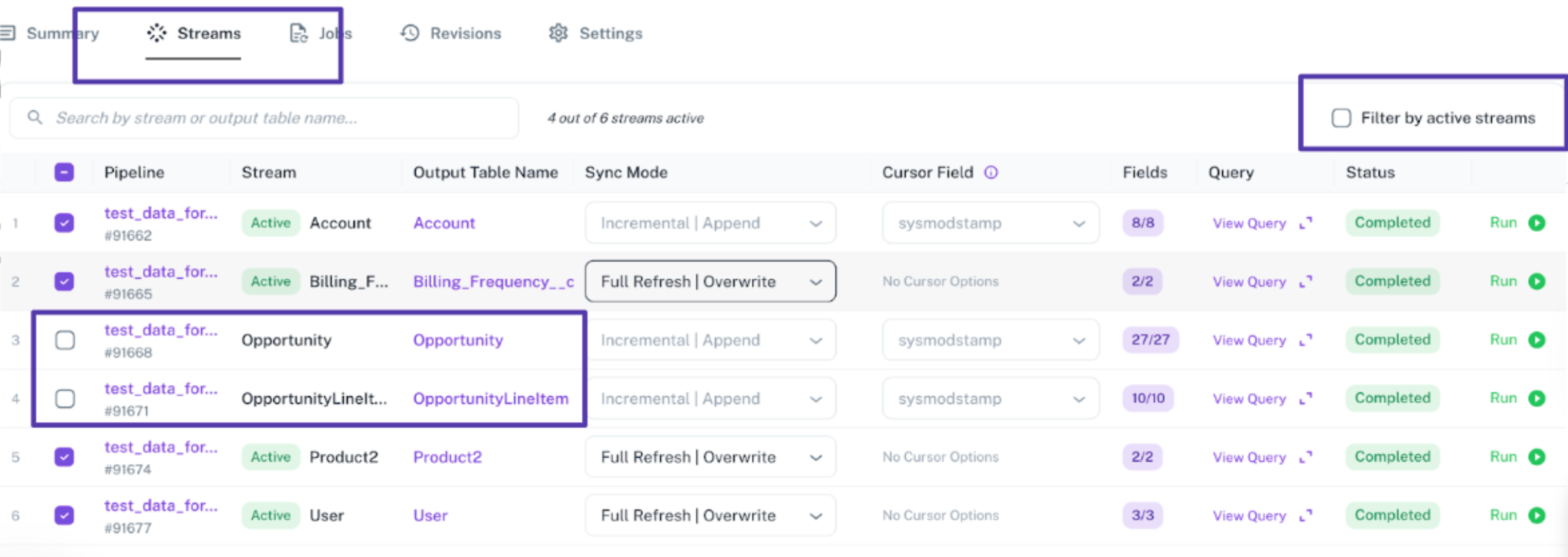
New stream selection
- Scenario: Adding a New Stream to an Existing STD or Dedupe Pipeline You have already created a standard or deduplication pipeline with a selected subset of streams. Later, you realize a new stream needs to be added.
- Solution:
- Navigate to the Pipeline page.
- Go to the Streams tab.
- Uncheck the Filter by Active Streams option to display all available streams.
- Select the new streams you want to include.
- Click Save Changes. From the next pipeline run onward, the newly added stream(s) will begin syncing and depositing data into your warehouse.
Sync modes in pipelines
DataGOL offers different types of sync for pipelines intended specifically for the different types of data movement from source to destination. Supported ones are as follows:
-
Full Refresh Overwrite
-
Full Refresh Append
-
Incremental Append
-
Full Refresh Merge
-
Incremental Merge.
For direct queries executed by users, incremental fetches may not align with the source data especially if the source system does not track all changes reliably (like with missing updated_at values). In these situations, Change Data Capture (CDC) based ingestion is recommended. However, CDC falls outside the scope of DataGOL.
Which one to use?
Each sync modes has its own specialities as mentioned below:
Full Refresh Overwrite
Transfers all data from the source to the destination, replacing existing data.
Implications:
-
A Full Refresh scans the entire source during each sync, which utilizes storage.
-
Storage: For data recovery we maintain a back up of the data and its deleted after 7 days.
-
Cost: Increased storage size leads to higher costs.
-
Computational heavy and in case of large data, incremental append is recommended
When to Use?
-
When you want a clean slate and entire data with each sync.
-
When data volume is small to moderate and updates are frequent or complex.
-
Simple use cases without incremental tracking.
Full Refresh Append
Loads all data from the source and appends it to the destination with each run, potentially creating duplicate records.
Implications:
-
With each sync, Full Refresh Append scans the entire source dataset and adds all records to the destination, regardless of changes. This process increases data volume with every run, resulting in higher storage consumption and potential data duplication, thus requiring a deduplication pipeline downstream.
-
Storage: For data recovery we maintain a back up of the data and its deleted after 7 days.
-
Cost: Increases due to storage size
-
Computational heavy and in case of large data, incremental append is recommended
When to Use?
-
For append-only logs or audit trails.
-
Appending is preferred to preserve the history of each sync.
-
When data deduplication will be handled downstream.
Incremental Append
Syncs only new or modified data since the previous sync and appends it to the destination without deleting existing records. While this approach requires the user to build de-duplication logic via dedupe pipelines, it offers the advantage of time travel or "AS OF" reporting, allowing you to restore or analyze historical snapshots of the data. Additionally, jobs can run in parallel if a partition column is defined in the source table, improving performance.
Implications:
-
Source Scan: During each sync, the source table is scanned based on the specified cursor field to detect changes.
-
Storage: To support atomicity and data recovery, a backup of ingested data is maintained for 7 days before being automatically deleted.
-
Cost: Typically lower than Full Refresh modes, as only the delta (new or updated records) is transferred, reducing data movement and storage needs.
Recommendation:
Indexing the cursor column in the source is highly recommended. This ensures the cursor column is efficiently scanned, significantly increasing data processing speed.
When to Use?
-
When your data source supports a cursor field (e.g., last updated time).
-
For efficient syncing of large datasets with frequent new entries.
-
When you need to analyze historical snapshots of the data using AS OF.
Full Refresh | Merge
Performs an upsert operation (inserting new records or updating existing ones) based on a unique key. Requires Iceberg format destination.
Implications:
-
Storage: To support atomicity and data recovery, a backup of ingested data is maintained for 7 days before being automatically deleted.
-
Cost: Increases since the entire data is captured along with the delta/changes.
When to Use?
-
When you want to upsert all records accurately each run.
-
If your system supports Iceberg format and merge/upsert logic.
-
For data sources with changing records where a full update is necessary.
Incremental | Merge
Efficiently updates a target table by syncing only changes since the last run, using a cursor to perform upserts. Requires Iceberg format destination.
Implications:
-
Storage: To support atomicity and data recovery, a backup of ingested data is maintained for 7 days before being automatically deleted.
-
Cost: Comparatively lesser than the full refresh merge sync mode since only the delta/changes is captured.
When to use?
-
For large datasets with partial, frequent updates.
-
When you want to minimize sync time and storage.
-
If the destination supports upsert logic and the source has a reliable cursor (For example: timestamp or ID).
For Full refresh merge and Incremental merge to work to its full capability it is important to mark a column as a unique column in the table present in the source. If missed, then Full refresh merge and Incremental merge operate as Full refresh append and Incremental Append respectively.
Steps to add unique column: Lakeshouse > Data Sources > Table > Column Info > Unique Column
What is a Cursor field?
A cursor field is a column in your source data that tracks when a record was created or last updated. It's used to identify what has changed since the last sync, enabling incremental data loading instead of pulling the entire dataset every time.
Which fields can be used as Cursor Fields
Prefer Updated_at, last_modified_date as it generally tracks both new and modified records. Able to identify new or changed data reliably.
How do I change the cursor field for my streams?
- Scenario: You initially used updated_at as the cursor field but now want to switch to last_modified for incremental syncing.
- Solution: Go to the pipeline, locate the associated stream, and delete the pipeline specific to that stream. This will automatically deselect the stream from the main pipeline's streams page. Then, select the required stream again, configure the sync mode and cursor field as needed, and save your changes.
AS OF time travel
When do you need AS OF time travel feature?
The AS OF time travel feature allows you to access historical data as it existed at a specific point in the past. This is particularly useful for:
-
Debugging: Analyze data from a previous state to help resolve issues.
-
Historical Analysis: Examine data from a specific point in time in history.
How to use the AS OF feature?
-
Create an Orchestration: Create an orchestration with necessary pipelines.
-
Parameterize the Orchestration: Update the queries to accept a timestamp or date parameter. In general, orchestration supports multiple parameters including strings.
-
Schedule with Dynamic Date Control: When scheduling the orchestration, utilize the default parameter settings to enable dynamic date control with functions like current_date(). Additionally, all the spark functions are supported as default parameters.
Important Considerations
-
Storage Impact: Leveraging the "AS OF" time travel feature increases storage usage. This is due to data being stored for different points in time, which creates multiple files and drives up storage costs, particularly for tables with large data volumes.
-
Performance: No impact on performance.
Dedup pipelines
A dedupe pipeline is a custom data pipeline designed to identify and remove duplicate records, ensuring that only the latest or most relevant version of each record is retained in your dataset.
When to Use?
-
When using Incremental Append syncs, systems often send multiple versions of the same record (e.g., after every update).
-
With Full Refresh Append, all records are re-added during each sync, leading to duplication over time.
-
Especially common with API-based or REST connectors like Salesforce, Cvent, etc., where updates are sent as new rows rather than modifying existing ones.
How It Works?
-
You define deduplication logic using a primary key (e.g., id, uuid) and a timestamp (e.g., updated_at, last_modified).
-
The pipeline keeps only the most recent version of each record by comparing timestamps.
-
This logic is implemented in a custom pipeline that runs after data ingestion.
Join across sources
-
Scenario: Data is sourced from multiple databases, each corresponding to different products, but there is a need to consolidate and store it in a single table within the data warehouse.
-
Solution: This can be accomplished using custom pipelines, which allow you to write SQL logic that joins and transforms tables across different sources, enabling unified data ingestion into a single destination table.
Iceberg vs Parquet
When to use?
- Parquet
- Data warehousing and analytics platforms: It's designed to store data efficiently on disk, especially for large datasets, and optimize performance for read-heavy analytics workloads.
- Efficient storage and fast querying: Parquet excels at storing data efficiently using columnar organization and compression techniques, making it ideal for scenarios where you need to query specific columns from a large dataset quickly.
Iceberg Transactional correctness and historical versioning: It supports ACID transactions, ensures data consistency even with concurrent writes, and allows you to query historical versions of the data (time travel).
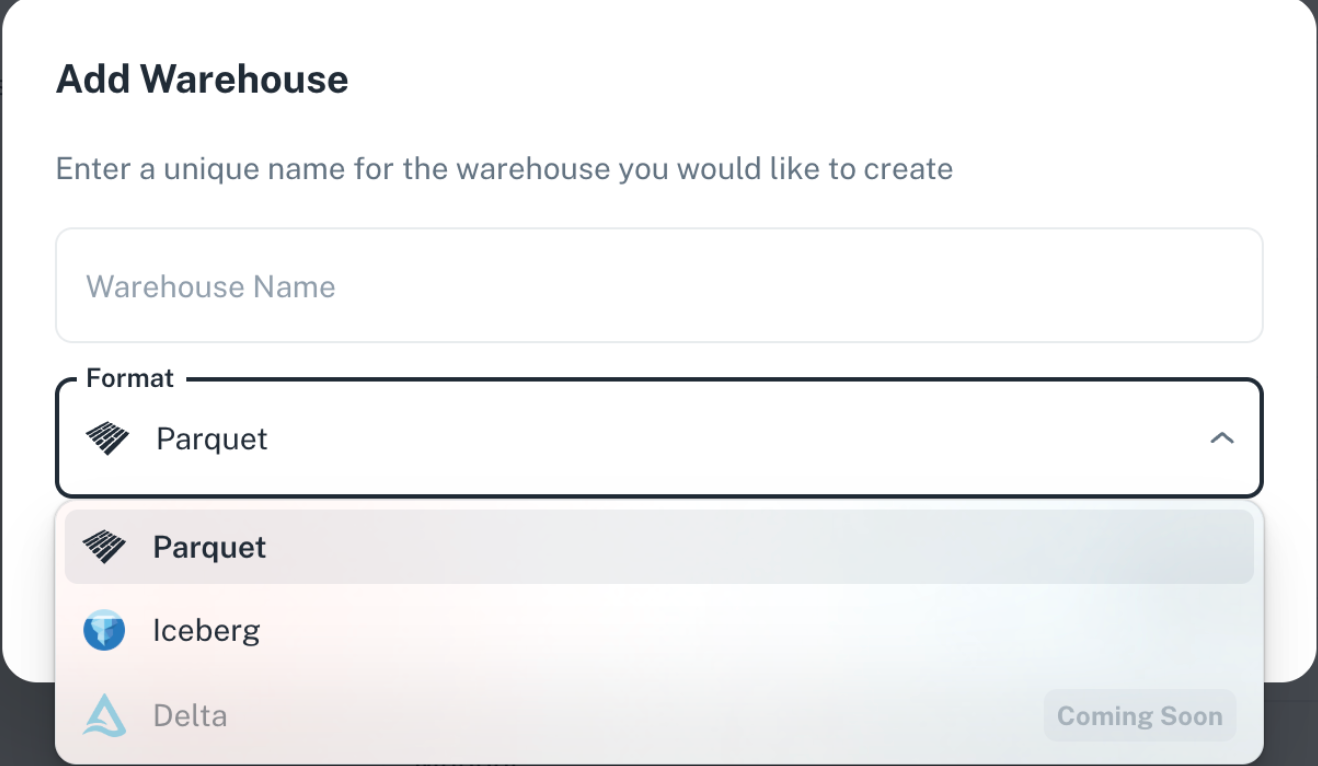
Lakehouse permissions
DataGOL features two distinct roles, Lakehouse Admin and Lakehouse Member, each with its own set of permissions.
When to U\use?
-
Lakehouse Admin Focuses on managing lake houses and their associated components. The Lakehouse Admin has the following permissions:
-
Lakehouse Management: Full control over lakehouses.
-
Data Source Management: Create, edit, view, and delete data sources.
-
Pipeline Management: Create, edit, view, and delete pipelines.
-
Job and Alert Management: View jobs and alerts.
-
Ideal for users:
-
Need to configure and manage data sources and pipelines end-to-end.
-
Oversee data ingestion, transformation, and flow monitoring.
-
Serve as engineers, or admins managing the full data lifecycle.
-
-
-
Lakehouse Member Designed for users who would need admin access only for the pipelines and the orchestrations they are invited to. The Lakehouse Admin has the following permissions.
-
Data Source Access: View data sources.
-
Pipeline Access: Members can edit, view and delete the pipelines to which they are invited to and can create MV pipelines but they will not be able to create a pipeline from lakehouse.
-
Orchestration Access: Members edit, view and delete the orchestrations to which they are invited to but they will not be able to create an orchestration.
-
Job and Alert Management: View jobs and alerts.
-
Ideal for users:
-
Need to manage pipeline configurations to only specific pipelines.
-
Require visibility into jobs, alerts, and data flows for monitoring purposes.
-
-
Workbooks and BI
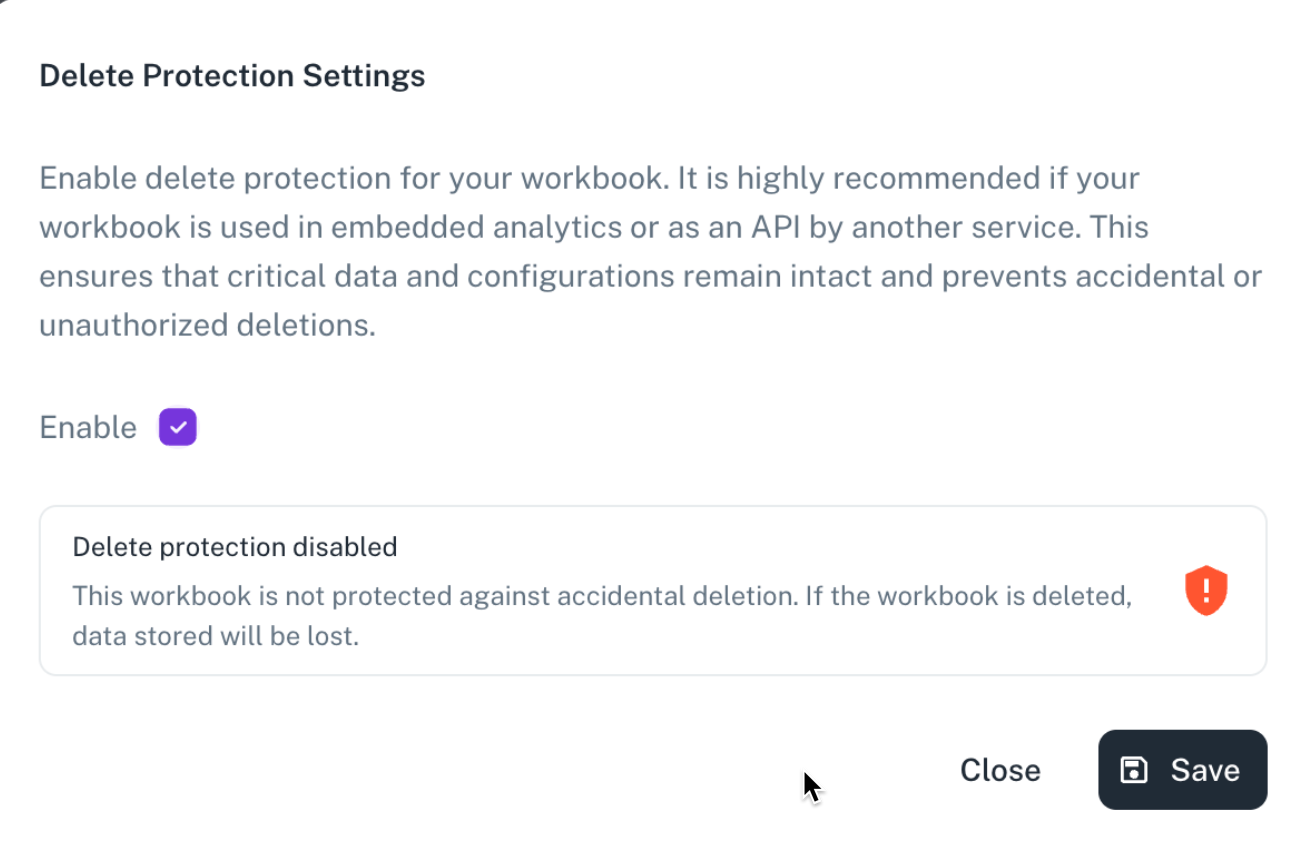
Delete protection
DataGOL offers a delete protection feature to safeguard your workbooks. Enabling this feature also ensures that your entire workspace is protected from accidental deletion.
Steps: Your_workspace > your workbook > Settings > Delete Protection > Enable
When to use? Enable this feature to safeguard important workbooks within a collaborative workspace from accidental deletion by other users. If delete protection is enabled for even a single workbook, the entire workspace will be protected.
It is highly recommended for finalized gold layer data and data sets which are exposed as API’s.
Golden layer - Workbook is the key
Maintain a clean data model layer, meaning a well-structured workbook. Address any inconsistencies, such as table column names or data types, directly within the playground using queries. This ensures data cleanliness and seamless integration in BI. It is mandatory to resolve these issues in the playground if found.
Naming Convention for workbook and view
For easy reference and future retrieval, ensuring the view name and workbook name are consistently aligned/same is highly recommended.
Sharing Workspace with users: editor and viewer access
Choosing between Editor and Viewer access when sharing a workspace can be tricky. If a user will be actively contributing to workbook creation or widget development, grant them Editor access. Otherwise, Viewer access is sufficient. For comprehensive details, please check the product manual.
Change of source after views and dashboards creation – Do you need to redo them?
Scenario: Once your views and dashboards are in place, there are two key situations where changes might occur: pipeline updates or source/warehouse changes. 1. Pipeline changes
-
Impact: No manual update required.
-
As long as the warehouse remains unchanged (i.e., the source powering your workbooks), the data will automatically refresh with each pipeline run.
-
Your workbooks will continue to reference the same warehouse.
-
Your dashboards will remain functional, powered by those workbooks.
-
Result: Dashboards update seamlessly—no action needed.
2. Source or warehouse changes
-
Impact: Manual updates might be required.
-
If the underlying warehouse changes, you must update all workbook queries to point to the new warehouse.
-
Ensure all columns used in the existing queries are present in the new warehouse with the same schema and data types.
-
If there’s no schema change, dashboards will auto-update once the workbook is corrected.
-
If columns are renamed, removed, or have datatype changes, manual intervention is needed to update both workbooks and dashboards accordingly.
Always verify column compatibility and test workbook outputs on the playground before relying on auto-updates.
Moreover, our Impact Analysis feature will help to ensure that we capture all the downstream impacts when there is a change in the source and one level up in the upstream. By this, the user will have a quick snapshot of all the impacted modules.
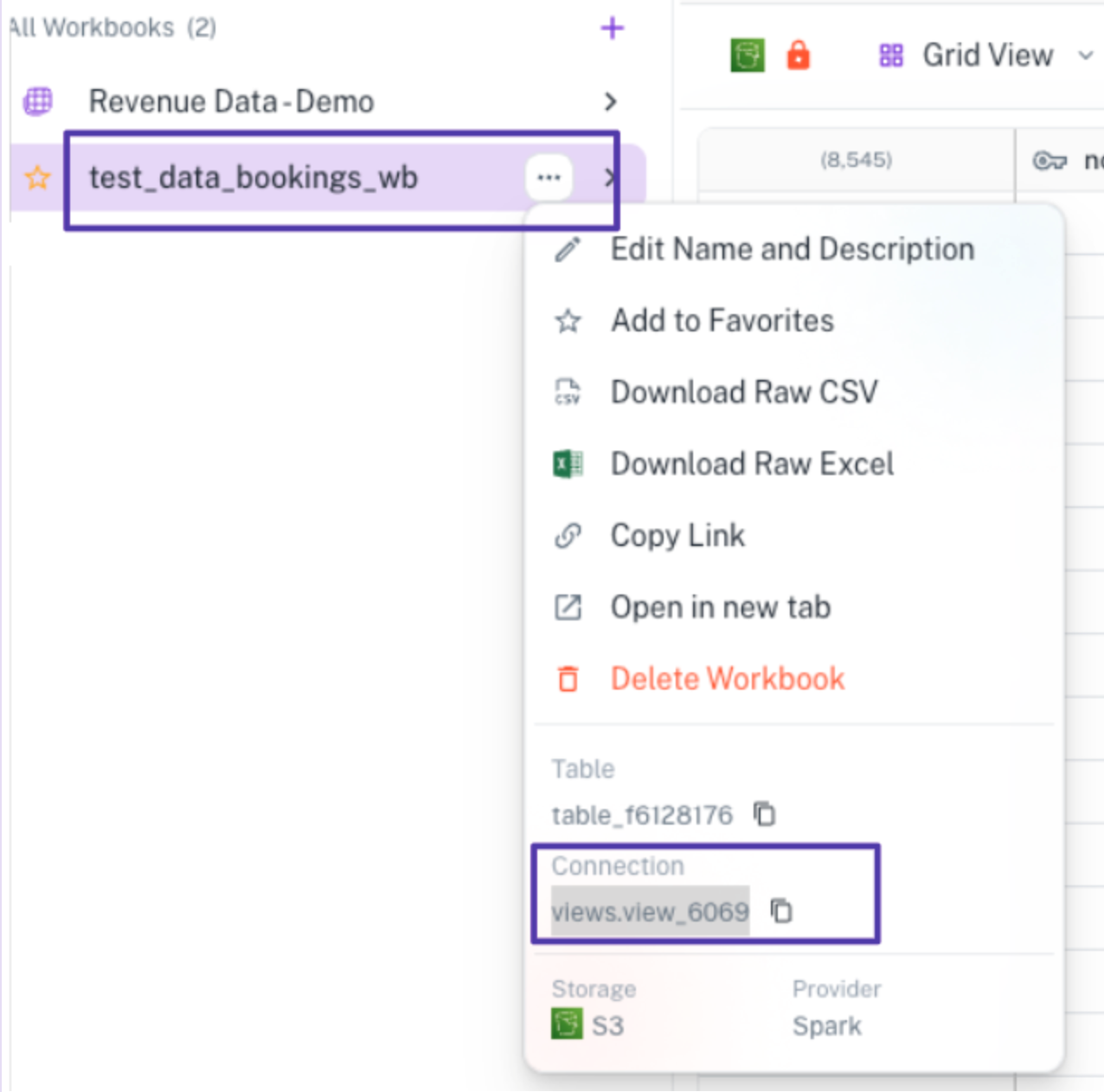
Joins between existing workbooks
Scenario: You have already created individual views for specific use cases, and now you want to reuse data from one workbook in another.
Solution:
- In the left-hand panel, click more options icon (three dots) next to the workbook you want to reference.
- Locate the connection name:
- If it’s a Spark-based workbook, it will show:
views.view_123 - If it’s JDBC-powered, it will show :
app_connection_read.table_123 - In the Playground, you can query these workbooks directly using query:
SELECT * FROM views.view_123
SELECT * FROM app_connection_read.table_123
- If it’s a Spark-based workbook, it will show:
Storage type
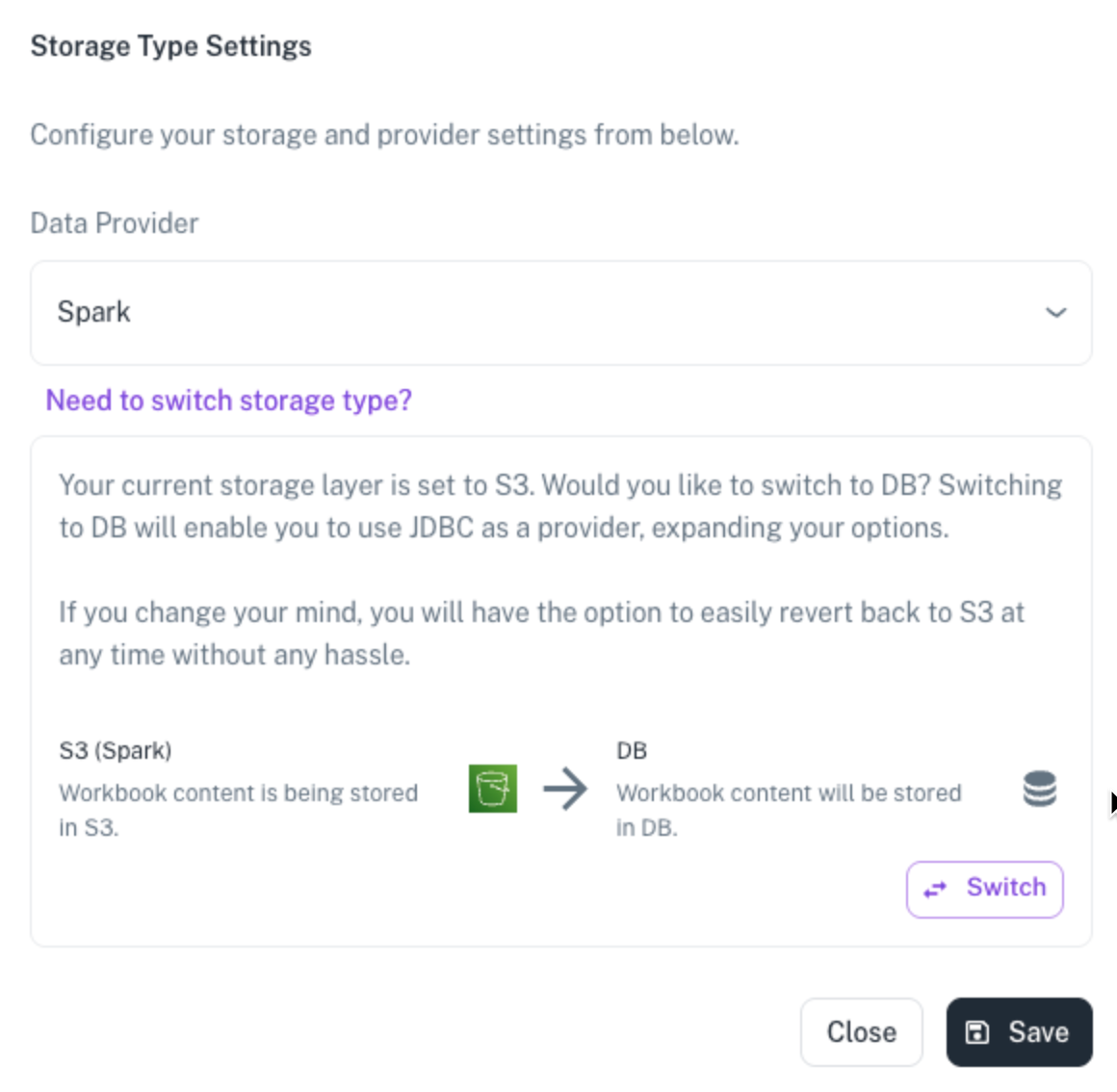
For handling larger datasets, utilizing Athena query engine is advisable. Users also have the ability to switch the storage type to use JDBC for faster data processing especially for medium sized data. This optimizes data loading speed on workbooks and BI dashboard. After updating the required provider in your workbook based on the use case, all BI visualizations created from that workbook will dynamically reflect the widgets based on the provider selected in the workbook.
Query engines
DataGOl supports 3 different types of Query engines designed for specific use cases as mentioned below,
-
JDBC: Designed to handle faster data retrieval for medium sized datasets.
-
Spark: Designed to handle large sized datasets.
-
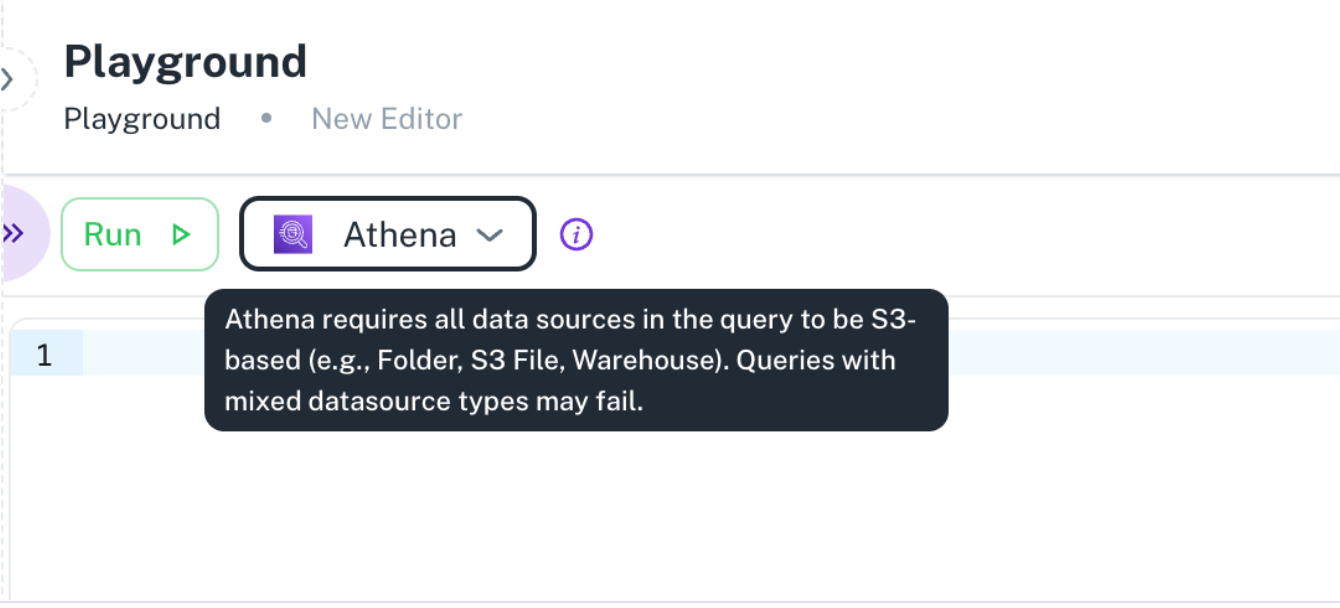
Athena: Designed to handle large datasets and faster data processing. However Athena has the below limitations,
- In the playground, Athena is supported only for S3 data source (Folder, s3 files and Warehouse).
- In workbooks, if the view is published via spark, the user has the capability to switch to Athena but it's not allowed when the view is published via JDBC.
Athena support on Playground:
Persistent layer
In DataGOL, the persistent layer refers to where the data is physically stored after it is ingested and made queryable.
-
For Spark and Athena workbooks, the data is persisted in S3 in an optimized, queryable format.
-
For JDBC workbooks, the data remains stored within the underlying database.
This persistence ensures that queries are run efficiently without repeatedly pulling data from the original source, improving performance and reducing load on source systems.
Steps: Your_workspace > your workbook > Settings > Storage and Provider Settings
Consider if a workbook was created using the views.view_id connection name of another workbook, and the latter workbook’s data provider type is later changed to a database (JDBC), resulting in the connection name switching to something like table_123, the original query using the views.view_id will continue to work without any impact.
Changing the query engine from Spark to Athena
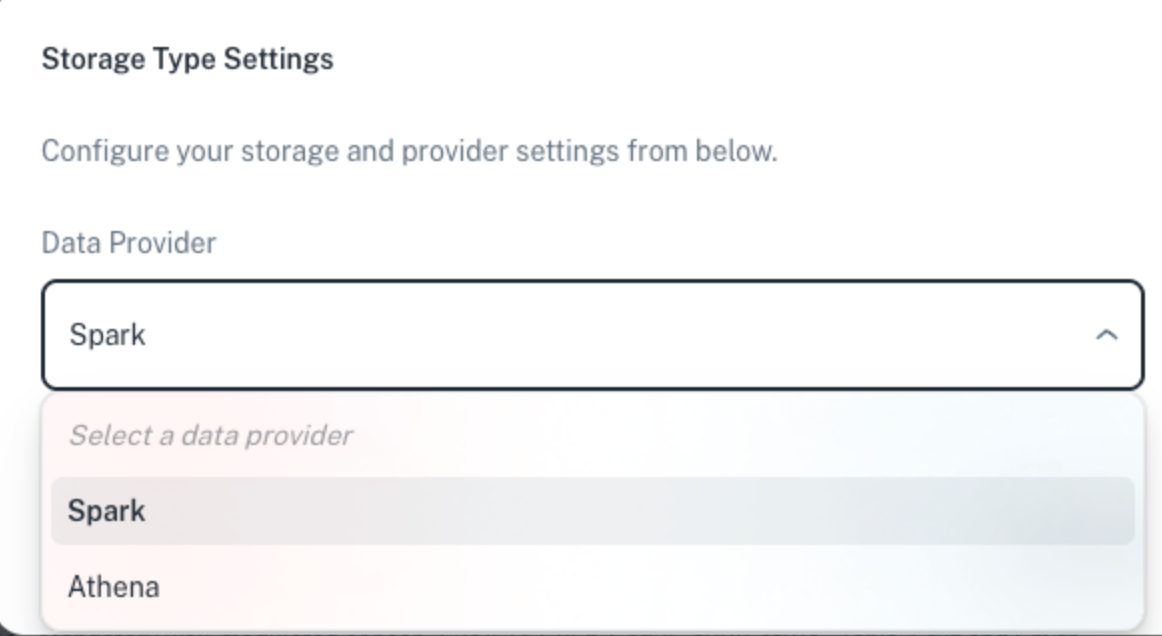
Switching Data provider from Spark to JDBC:
BI query integration
DataGOL supports BI Query Integration to allow dynamic parameters passing directly into SQL queries. When parameters are added in the Visualizer, they are injected into the query at runtime. As a result, widgets on the dashboard render context-specific data based on the selected parameters, with queries executed dynamically in the backend.
When to use?
When you want to build dashboards with interactive parameters, such as time range, region, product, or user-based filtering.
Limitations:
-
No Reusability Like Views: BI workbooks cannot be referenced in other queries (e.g., using views.view_123), making them less reusable outside of their dashboards.
-
Scoped to Dashboard Context: BI workbooks are designed specifically for dashboards and do not appear in the workbook list on the left panel in the workspace.
-
Restricted Query Sources: BI queries can only be built on top of existing workbooks using view IDs or table IDs. They do not support querying directly from data sources or warehouses.
Workbook and BI formula support
Formula functionality in DataGOL is dependent on the underlying connection type of the workbook: Spark or JDBC.
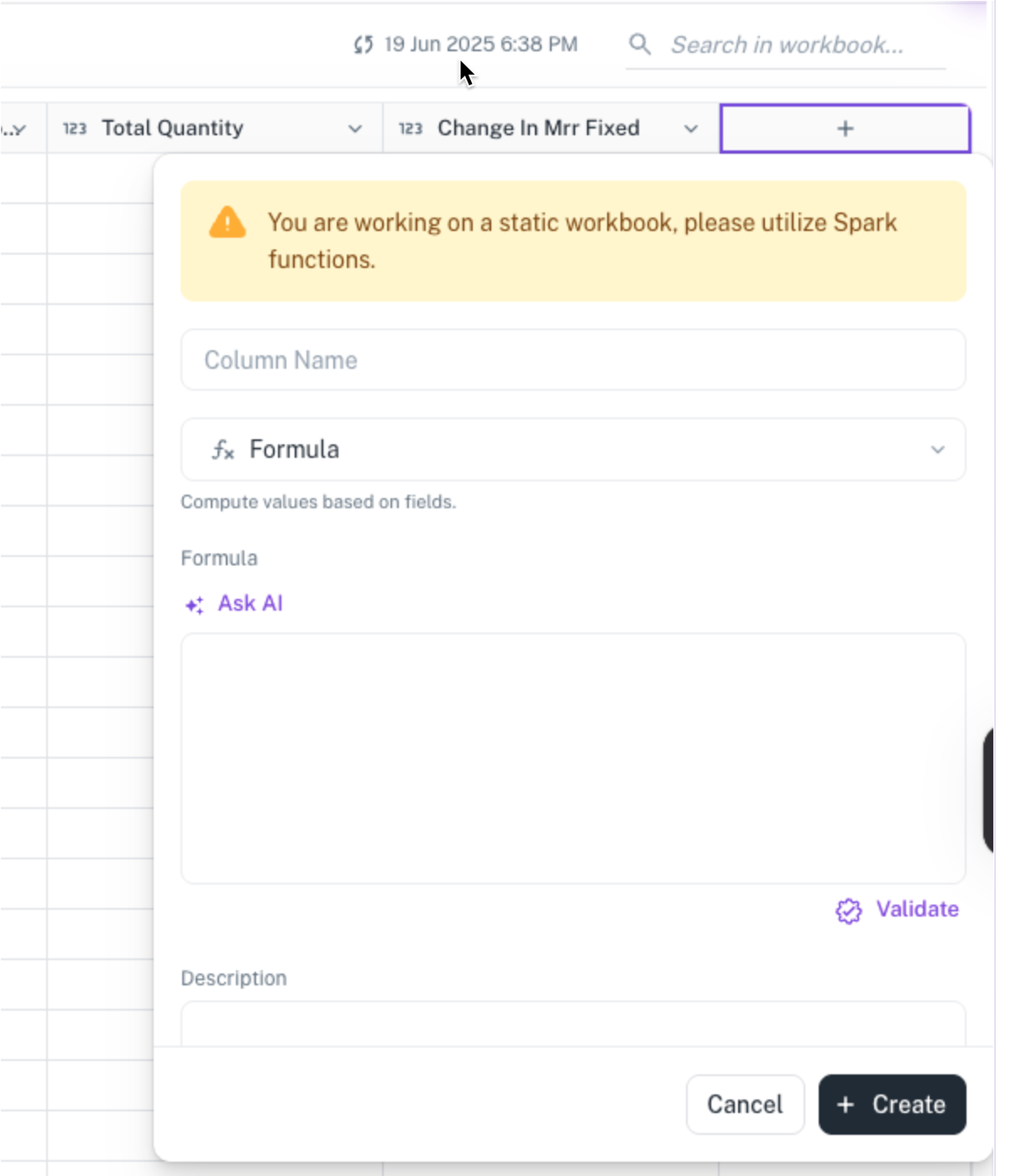
In Workbooks
You can create formula columns directly using the functions supported by the data provider type.
-
If the workbook is based on Spark, use Spark-supported functions.
-
If the workbook uses a JDBC connection, only JDBC-compatible functions can be used.
Creating Formula Column on Workbooks:
 `
`
In BI (Visualizer)
Formula columns created in the Visualizer inherit the function support from the underlying workbook.
-
If the workbook is Spark, the BI formula column will support Spark functions.
-
If the workbook is JDBC, the BI formula column will support JDBC functions.
Always check the workbook’s data provider before writing formula logic in BI or workbook to ensure compatibility.
Steps to check storage type: Your_workspace > your workbook > Settings > Storage and Provider Settings
Creating formula column on BI:
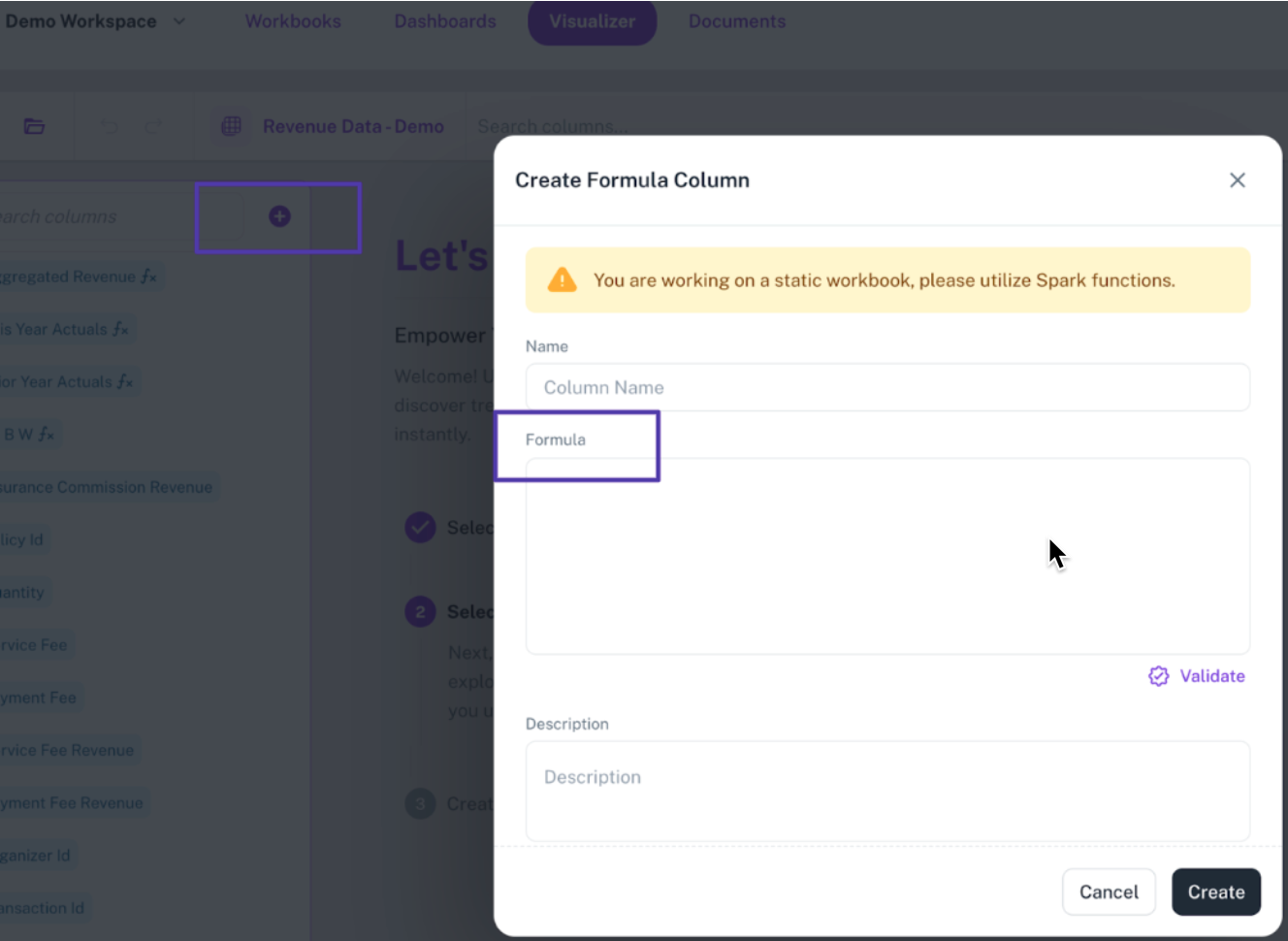 `
`
Playground
Data cleaning via queries
To achieve a refined and pristine data layer, the Playground is central for all data manipulation at the query level. Within Playground, you can execute queries, review the resulting data, and upon validating its cleanliness, create a view such that the query is saved and finally publish it as a workbook.
Adding a limit
To optimize performance when working with large datasets, it's best to start by applying a query limit. This helps speed up data retrieval and reduces response times. Once the query logic is validated, you can remove the limit to generate the full view.
Running unbounded queries (without limits) on large datasets can be slow and costly if done accidentally.
The Playground is a useful space for ad hoc analysis and safely testing queries before use.
Example: select * from source.table limit 50
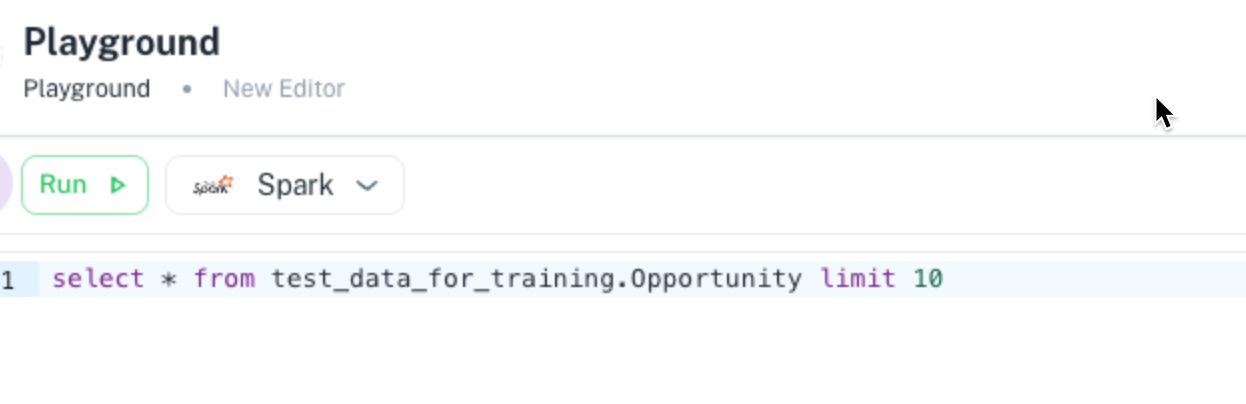
Troubleshooting steps for common Spark errors
Out-of-memory Issue
Driver failure caused by an out-of-memory error, resulting in query or job failure. Possible causes could be as follows:
-
Insufficient memory allocated to the driver for the query or job.
-
Execution of large or complex queries that require more memory than available.
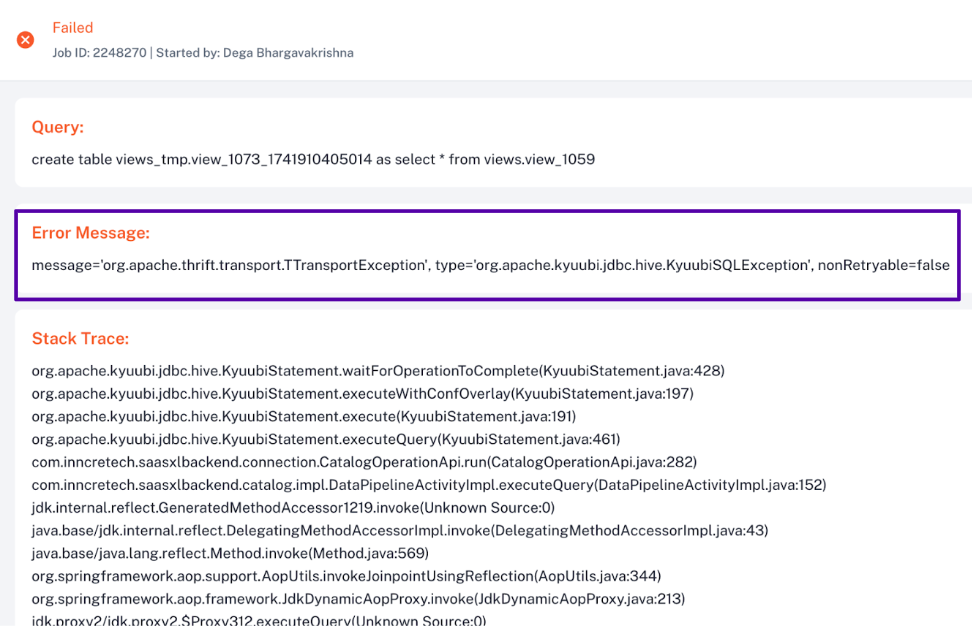
Troubleshooting options:
-
Memory Adjustment (Backend): Currently, users cannot adjust driver memory from the UI. Memory configuration changes must be made in the backend. DataGOL team can help with this.
-
Query Optimization: Optimize the query to reduce memory usage (e.g., filter data early, reduce data shuffles).
-
Partition Column: When working with large datasets (e.g., over 200 million records), adding a partition column to the tables used in the query can significantly improve performance and help prevent memory-related failures.
-
Incremental Append: Switching the sync mode to Incremental Append can also help mitigate the issue, as it processes only the data delta rather than the entire dataset.
-
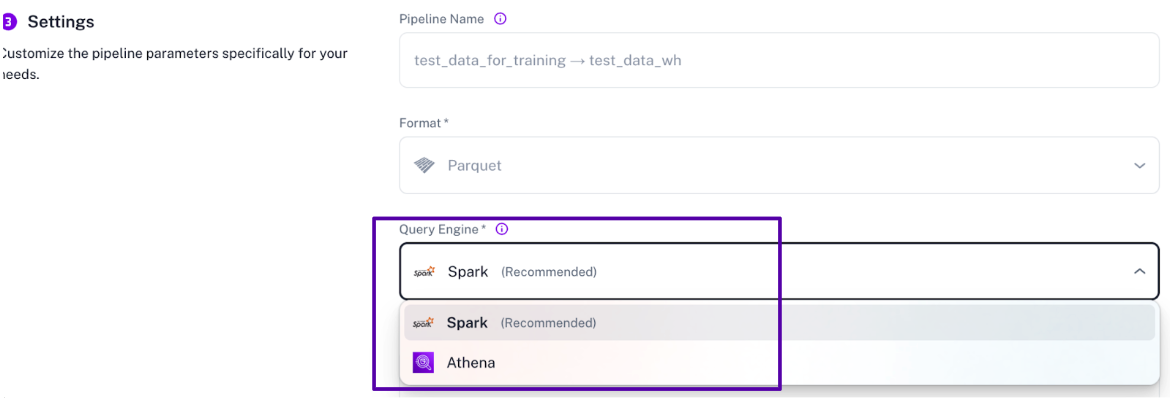
Athena Query Engine: During pipeline creation process, utilizing Athena as query engine will help mitigate the OOM issue. Athena as Query Engine during Pipeline Creation:
Kyuubi down/No active Kyuubi
Scenario:
- Error message: `Unable to read HiveServer2 configs from zookeeper" (Zookeeper Hides Client Exception)
- Playground Queries or Pipeline jobs failures.
Root cause analysis:
-
Kyuubi idle timeout (30 minutes of inactivity).
-
Kubernetes killing Kyuubi pods (potential memory issues or other unknown causes).
-
Both Kyuubi instances are down. (Rare, due to Zookeeper high availability)
Troubleshooting:
-
Retry: The system has built-in retry mechanisms (3 retries in playground, 5 in pipelines). Retry the failed query or job after a short delay (30-40 seconds).
-
Wait: QB instances typically recover automatically within 30-40 seconds.
-
Note: The platform uses Zookeeper for high availability (HA) with two Kyuubi instances. If both are down, this error will occur.
Important considerations:
-
Auto-Recovery: Both Apache Kyuubi and Spark driver failures have auto-recovery mechanisms.
-
Retry Logic:
-
Playground: 3 retries for Kyuubi-related failures (requires code update for Zookeeper exceptions).
-
Pipelines: 5 retries for any failure.
-
General reference
-
Most recommended Medallion Architecture: Medallion Architecture is a structured, layered approach to data management that enables the progressive enhancement of data quality and structure as it flows through three key stages: Bronze, Silver, and Gold.
-
Bronze layer:
This layer captures raw, unprocessed data with minimal transformation, often retaining essential metadata such as ingestion timestamps. It enables data lineage, historical archiving, and supports reprocessing without needing to re-extract data from the original source. -
Silver layer:
Data is cleaned, deduplicated, and transformed to enforce schemas and data types using SQL logic. This layer delivers reliable and standardized views, forming a trusted foundation for analytics and further analysis. -
Gold layer:
The final layer provides business-ready, optimized datasets, often denormalized and aggregated for consumption by BI dashboards for advanced analytics. It is tailored for high-performance access and user-friendly insights.
-
As data progresses through these layers, it undergoes enhanced quality control, governance, and structural refinement. The architecture supports ACID compliance, time travel, and incremental data processing, aligning with the lakehouse paradigm to deliver scalable, flexible, and traceable data pipelines.
Contact Us
Please feel free to contact us via Slack or email at support@datagol.ai for questions or concerns. Happy to help!