Spark exception and troubleshooting
This guide aims to provide troubleshooting steps for common Spark errors encountered within the DataGOL platform, specifically related to Apache Kyuubi and Spark Driver failures.
Key error scenarios
The following key error scenarios are observed:
Kyuubi down/No active Kyuubi
-
Symptoms:
-
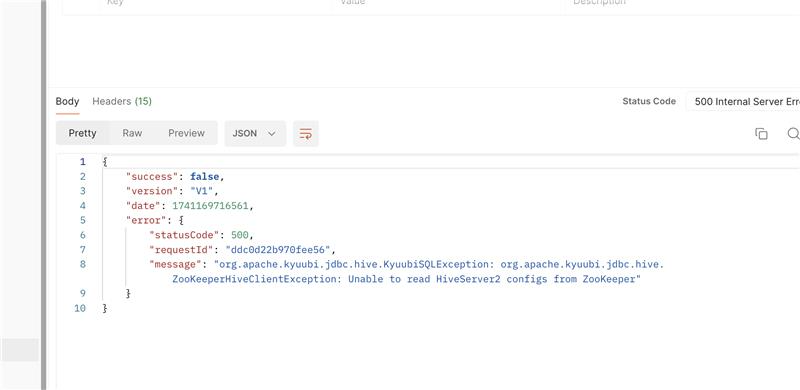
Error message:
Unable to read HiveServer2 configs from zookeeper(Zookeeper hides client exception). -
Playground queries or Pipeline jobs failures.
-
-
Causes:
-
Kyuubi idle timeout (30 minutes of inactivity).
-
Kubernetes killing Kyuubi pods (potential memory issues or other unknown causes).
-
Both Kyuubi instances are down. (Rare, due to Zookeeper high availability)
-
-
Troubleshooting:
-
Retry: The system has built-in retry mechanisms (3 retries in playground, 5 in pipelines). Retry the failed query or job after a short delay (30-40 seconds).
-
Wait: QB instances typically recover automatically within 30-40 seconds.
-
Note: The platform uses Zookeeper for high availability (HA) with two Kyuubi instances. If both are down, this error will occur.
-
Driver down (Out of memory):
-
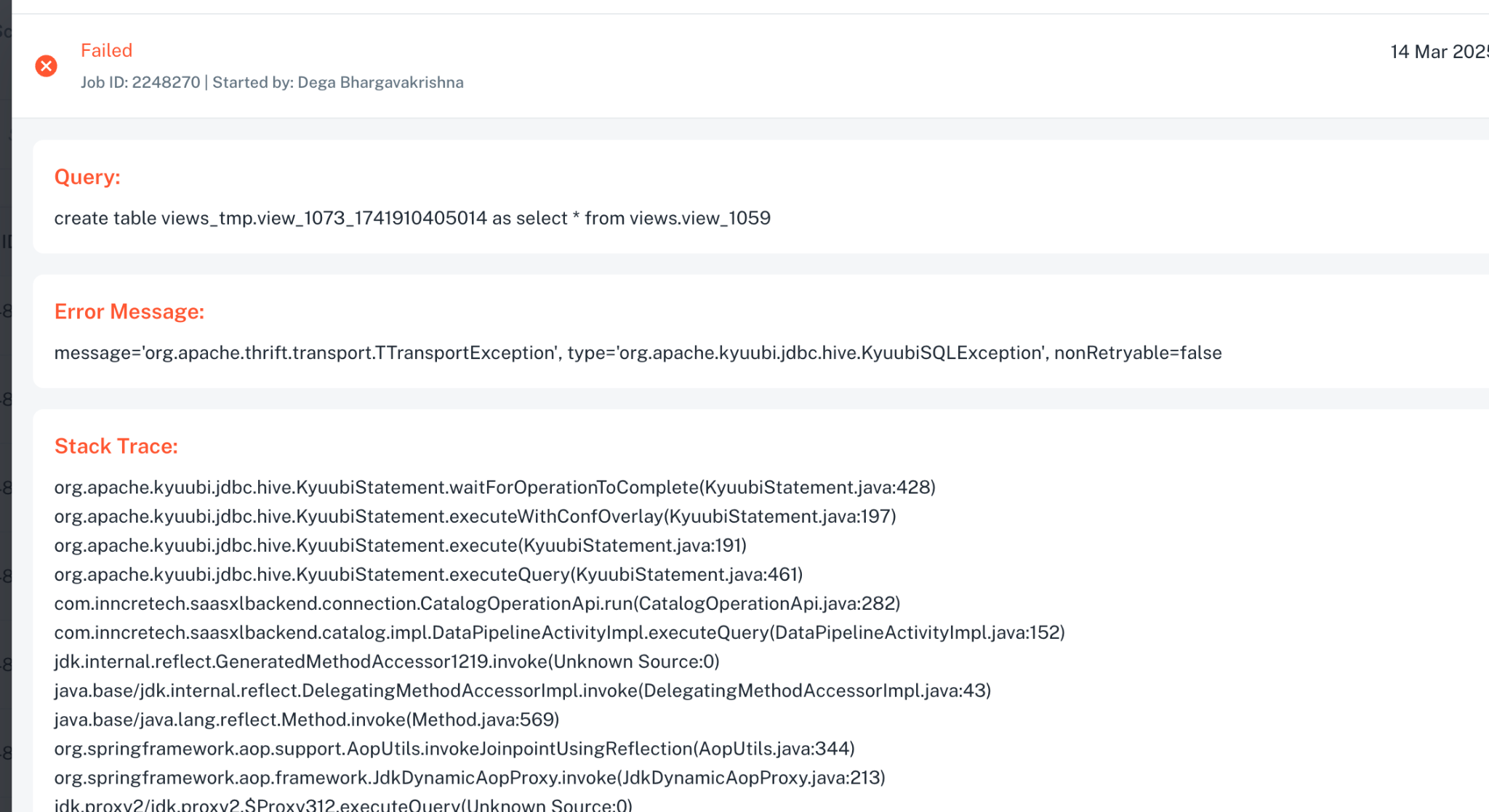
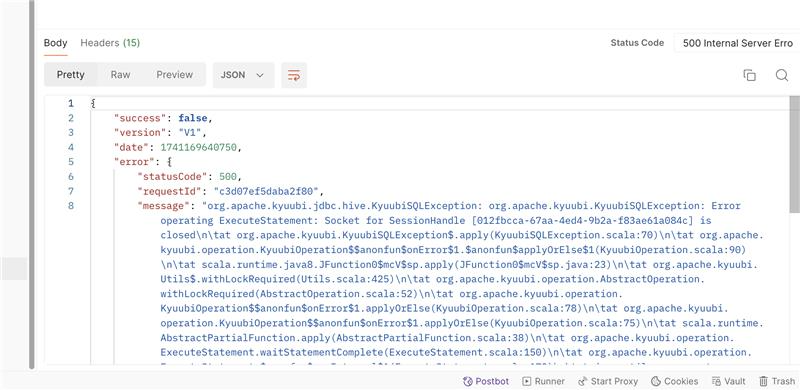
Symptoms:
-
Specific exception indicating driver failure due to out-of-memory error.
-
Queries or jobs fail.
-
-
Causes:
-
Insufficient driver memory for the executed query or job.
-
Large queries or data sets.
-
-
Troubleshooting:
-
Retry: While auto-recovery happens, retrying the same query without addressing the memory issue will likely result in the same error.
-
Memory Adjustment (Backend): Currently, users cannot adjust driver memory from the UI. Memory configuration changes must be made in the backend. Contact the platform administrator for assistance.
-
Query Optimization: Optimize the query to reduce memory usage (e.g., filter data early, reduce data shuffles).
-
Important considerations:
-
Auto-Recovery: Both Apache Kyuubi and Spark driver failures have auto-recovery mechanisms.
-
Retry logic:
-
Playground: 3 retries for Kyuubi-related failures (requires code update for Zookeeper exceptions).
-
Pipelines: 5 retries for any failure.
-
-
Kubernetes killing Kyuubi pods:
-
Kubernetes may kill Kyuubi pods due to resource constraints (e.g., memory).
-
The exact root cause is not always clear.
-
Zookeeper HA minimizes the impact of this issue.
-
-
Performance impact:
- After a Kyuubi restart, the first request may experience a delay (30-35 seconds) as the server warms up. Subsequent requests should be faster.
-
Cost optimization:
-
Kyuubi instances are automatically shut down after 30 minutes of inactivity to save costs.
-
The platform has a setting that can change the idle time before shutdown.
-
-
Zookeeper:
-
Zookeeper is used for high availability of the Kyuubi instances.
-
It helps to route traffic to available Kyuubi instances when one fails.
-
Zookeeper exception errors mean that no active Kyuubi instances are currently available.
-
Recommendations
-
Monitor Kyuubi and driver resource usage to identify potential memory issues.
-
Optimize queries to reduce resource consumption.
-
Implement code changes to correctly handle Zookeeper exceptions in the platform's retry logic.
-
Investigate and address the root cause of Kubernetes killing Kyuubi pods.
Was this helpful?