FAQs
What SQL dialect and functions are supported?
By default, Spark is selected, but you have the flexibility to change it based on your data source. DataGOL supports both Apache Spark™ SQL and JDBC dialects based on the data provider selected within the Playground.
For relational databases such as PostgreSQL, MySQL, and others, you can leverage JDBC-based queries, utilizing the SQL functions supported by the native database.
When querying data from data warehouses, folder datasources, or constructing queries on top of existing views, Apache Spark™ SQL should be employed. Apache Spark™ functions can be referenced here.
Athena is supported for faster data retrieval and applicable only for S3 data.
BI and Visualizer
How does the BI dashboard layer operate in DataGOL?
Dashboards are built on top of workbooks using a Visualizer. They support:
- KPIs, Line chart, Bar chart, Donut chart, Pivot tables, etc.
- Drill-downs, Filters, and exploration mode.
Key Points:
- Widgets use formulas and parameters
- Widget-level filters override page-level filters.
- Drill-downs can be column-based or widget-defined.
Data Sources
How does DataGOL handle deleted records in source systems like SAP?
Deleted records are handled using Full Refresh Merge with Iceberg, which compares snapshots to detect deletions.
Key Points:
- CDC pipelines are not directly supported in DataGOL.
- Full refresh merge provides a reliable internal alternative.
How should we name data sources and warehouses?
Best practice:
- Format:
<ProductName>_<Environment>_<DB|Warehouse> - For S3, replace DB with S3.
Example:
app_prod_db, app_stage_wh
This naming helps differentiate between DB, warehouse, and S3 sources clearly and ensures uniqueness for use-case-driven design.
How to define the S3 bucket path when adding an S3 data source.
S3 path format:
The S3 bucket path must extend to the location where the files exist.
Example: If your files are located at bucket/folder_1/folder_2/<files>, enter the path as bucket/folder_1/. The final folder folder_2 will be used as the table name in DataGOL.
<bucket>/<base_folder>/<table_name>/<files>
Provide a self-described folder name for generating logical table names.
Give the path up to the base folder. DataGOL processes each subfolder (e.g., table_name) as an individual table.
Schema Tips:
- Keep data types and column names consistent.
- S3 data source supports: CSV, Parquet, and JSON.
How to onboard 3rd party connectors (PostHog, HubSpot, etc.)?
Do the following to onboard 3rd party connectors:
-
Contact support team to whitelist connectors.
-
Once whitelisted, you can create a new data source from the Data Sources page with the appropriate connector and active credentials.
cautionPlease provide the start date wherever applicable else DataGOL will default to replicating data from the past year.
-
Create a pipeline from the data source.
Some APIs send updated data as separate records. In such cases, deduplication pipelines are essential to ensure you retain only the most recent version of each record.
What is a partition column and when to use it?
The partition column is used to create parallelism in Spark. Based on the partition column selected, multiple jobs will be created to minimise the time consumption for job processing. The default partition size is 50,000.
Partition columns are supported only for SQL datasources.
When should you use a partition column?
You should use a partition column feature, when a pipeline is created to move a large dataset to a warehouse, it significantly increases the job completion time.
How do you use a partition column?
To designate a partition column:
-
Navigate to the data source page for which you want to AI generate the metadata catalog.
-
Go to the Tables tab and click the link of the specific table you wish to catalog.
-
In the Table Info page, click the Column info tab.
-
From the extreme right click the more options icon corresponding to a column and select the Make partition column option. This option is available only for columns with following data types: int, bigint, timestamp, long, and date.
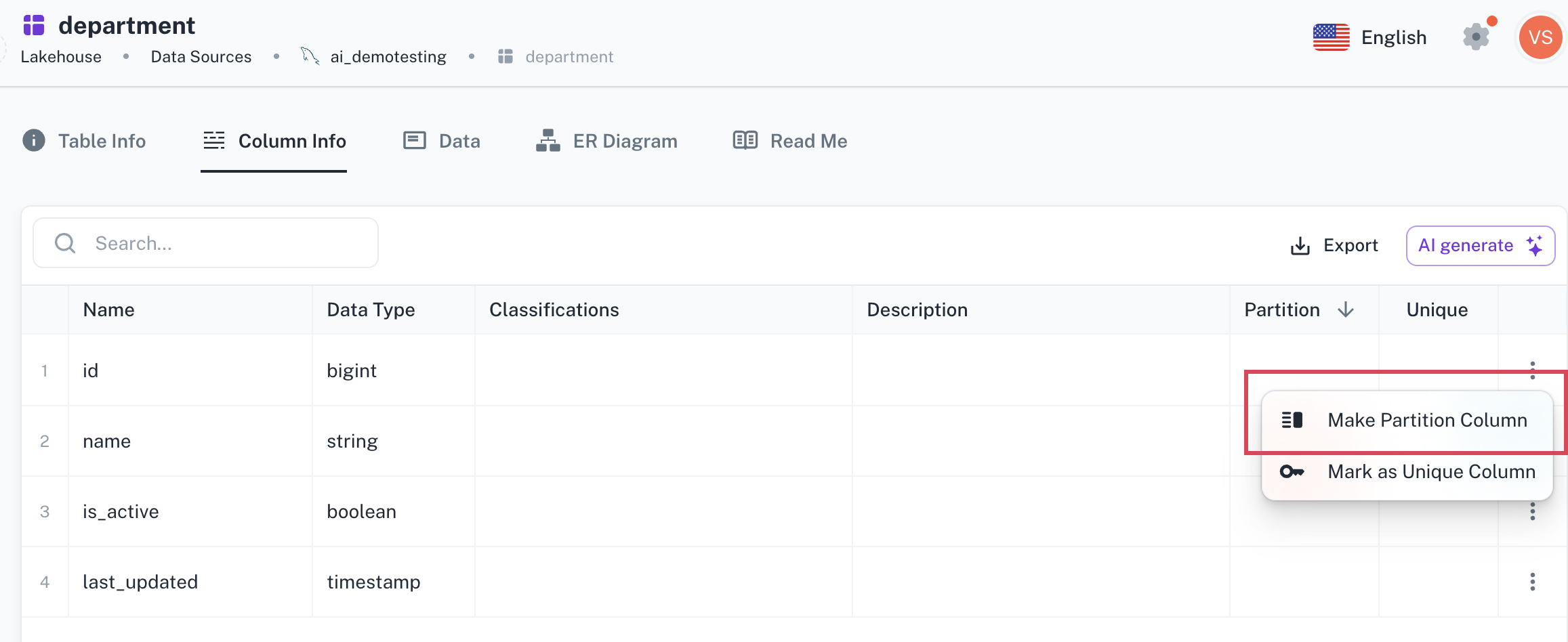
-
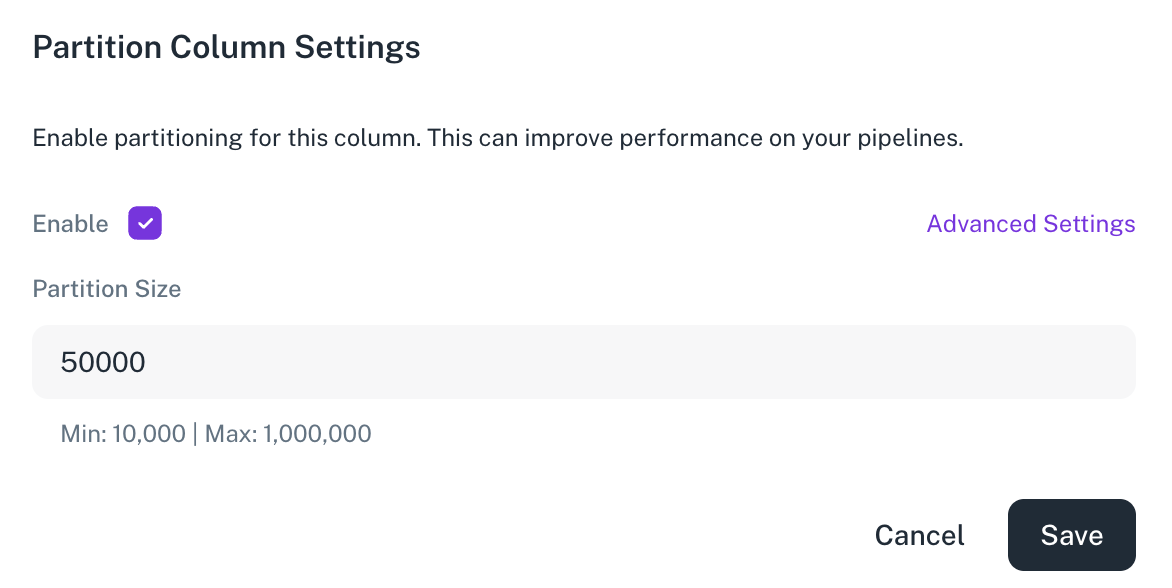
In the Partition Column Settings box, select the Enable checkbox. You can also click Advance Settings and specify the partition size.
The column that is specified as the partition column is ticked in the listed.
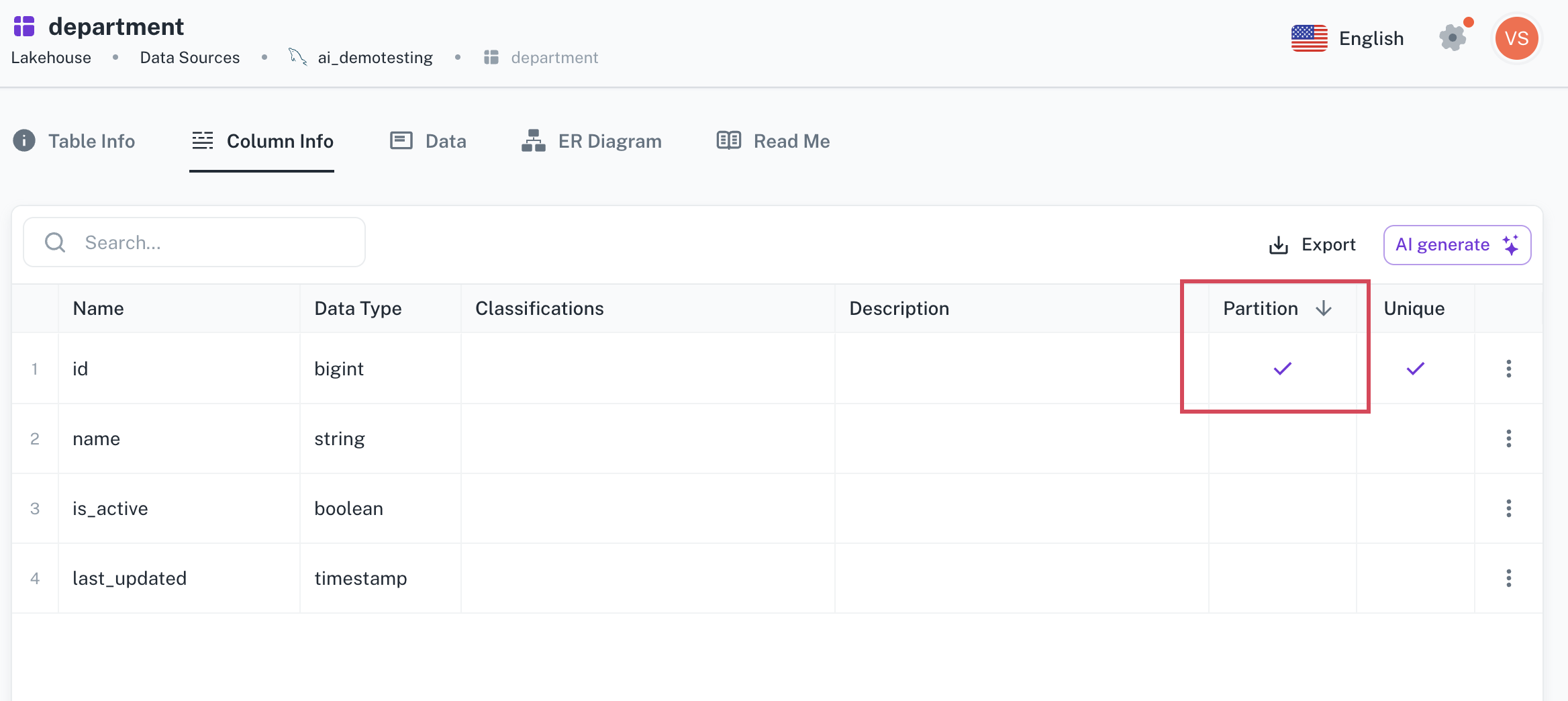
The designated column will be used as the partition column by Apache Spark while processing datasets. Only a single column can be used as a partition column. The default partition size is 50K.
infoThis setting is available only for RDBMS data sources.
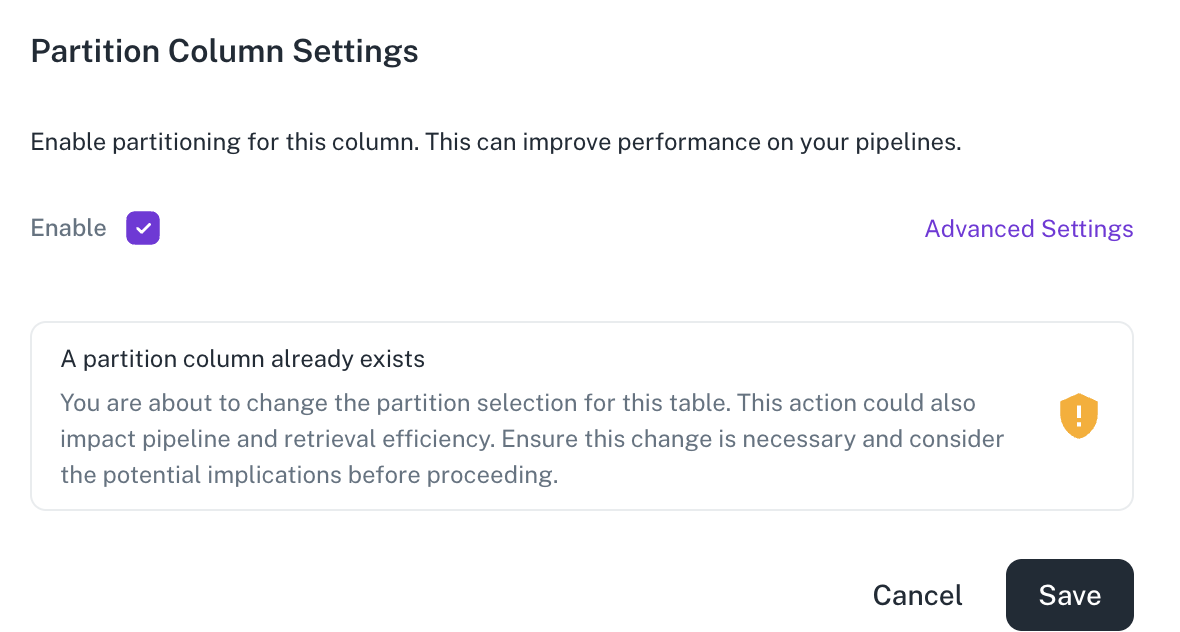
warningIf you attempt to change the partition column, a warning is displayed, since this action can impact the pipeline and retrieval efficiency.
What happens when the sync schema fails and the tables show as 0?
If your datasource is S3, make sure the path to the S3 bucket is correct, for third-party and other DB sources, confirm if the credentials are valid and active. If the issue persists, contact the Support team.
Can I write queries joining multiple sources?
Yes, you can join data from multipe data sources (for example, PostgreSQL, MySQL, warehouse etc.).
How to join data from multiple sources?
There are two options available: Custom Pipelines and Playground to create workbook from different sources.
-
Custom pipelines: Custom pipelines support custom queries, where the user has the flexibility to write joins on multiple data sources.
-
Playground: From Playground, you can write SQL queries using Spark. With Spark as the provider, you have the flexibility to write join queries on multiple data sources.
Lakehouse
What are the roles applicable for Lakehouse?
DataGOL supports two roles specific to Lakehouse - Lakehouse Member and Lakehouse Admin. See Roles and permissions for more details.
Pipeline
What are the available pipeline types in DataGOL, and when should each be used?
DataGOL supports three pipeline types:
- Standard Pipelines: Used for straightforward replication of source tables with sync modes. Good for raw replication with minimal transformation.
- Custom Pipelines: Designed for SQL-based transformations like joins, format changes, or business logic. Required when transforming time formats, handling nulls, or merging sources.
- Dedupe Pipelines: Remove duplicate records when systems (e.g., Salesforce) retain updated rows as separate entries. Best suited for systems that log updates as new records; used to identify and retain only the latest version of each record by removing duplicates.
Can users transform data types, nulls, or time formats in standard pipelines?
No, such transformations require custom pipelines where SQL queries can be written to clean and reformat data.
Key Points:
- Use the Playground if transformations need to be handled before creating the workbook.
- Use a custom pipeline to handle transformations to push it to the warehouse.
What are the different sync modes?
| Sync Mode | Description | Notes |
|---|---|---|
| Full Refresh Override | Overwrites all data each sync. | Storage-intensive. Use rarely. |
| Full Refresh Append | Adds all data every time (even duplicates). | Needs a dedup pipeline. |
| Incremental Append | Adds only new data based on the cursor field. | Most efficient, supports time travel. |
| Incremental Merge | Efficiently updates a target table by syncing only changes since the last run, using a cursor to perform upserts. | Requires an Iceberg destination. Performs an upsert operation (inserting new records or updating existing ones) based on a unique key. |
| Full Refresh Merge | Performs an upsert operation (inserting new records or updating existing ones) based on a unique key, effectively updating a target table. | Requires an Iceberg destination. |
When and how should we use dedup pipelines?
Use Case:
- Required for REST connectors (HubSpot, Salesforce, Cvent) or pipelines where every update is produced as a new record.
- Append modes where duplication is expected.
Setup:
Create a dedupe pipeline with the source as the warehouse with duplicates and the destination as the cleaned warehouse. Custom SQL logic can be applied for each stream to retain the latest records. The default dedupe logic (e.g., Salesforce-oriented) may not work for other connectors.
Custom SQL logic can be applied for each stream to retain the latest records.
What sync modes are supported in standard pipelines?
Available sync modes include:
- Full Refresh Override
- Full Refresh Append
- Incremental Append
- Incremental Merge
- Full Refresh Merge
Key Points:
- Incremental Append is optimal for performance and requires a cursor field.
- Full Refresh Merge is useful for detecting deletes via Iceberg snapshot comparison.
What are the destination formats and query engines supported in pipelines?
Supported formats:
- Parquet (default)
- Iceberg (for snapshot & merge functionality)
Query Engines:
- Spark SQL (Default - supported in Playground and Lakehouse)
- Athena (Supported in Playground and Lakehouse)
- JDBC - (Supported in Playground only and not recommended for large datasets).
Key Points:
- Parquet/Iceberg are disabled if using SQL dbs as destination.
- Choose Athena or Spark based on scaling and partitioning needs.
Where can users inspect and debug pipeline execution?
- Jobs Page: Shows execution status, time, and logs.
- Streams Page: Displays selected source tables.
- Revisions Tab: Tracks config changes.
Key Points:
- Supports immediate runs and scheduled/cron executions.
- Each revision preserves historical config.
Intermediate Views vs Intermediate Warehouses – Which is better for performance?
Recommendation:
Create a multi-layered data model:
- Bronze: Raw data.
- Silver: Cleaned, transformed.
- Gold: Final semantic view.
Avoid deeply nested CTEs. Instead, break logic into multiple views using pipelines — more performant and maintainable.
How to update the cursor field in an incremental append sync mode?
If you need to update the cursor field for a stream configured with incremental append sync mode, you cannot directly change it within the existing pipeline. This is because once incremental append is selected, direct modifications to the cursor field are not permitted. Here's the workaround:
- Delete the specific stream's pipeline:
- Navigate to the main pipeline that contains the stream you wish to modify.
- Identify the pipeline corresponding to that particular stream.
- Delete this individual stream's pipeline. This will remove the stream from your main pipeline.
- Re-add the stream with the desired cursor field:
- Go back to your main pipeline. The deleted stream will no longer be present.
- Search for and re-select the stream you just removed.
- When adding it back, select the incremental append sync mode again. Now you will be able to choose your desired cursor field (e.g., "last modified" instead of "ID"). 4, Save your changes.
How to manage large APIs like HubSpot if pipelines timeout?
Solutions:
- Reduce the number of streams per pipeline.
- Use incremental Append mode wherever possible.
- If the HubSpot connector does not support this, segment the workload across multiple data sources.
- Restrict the start date (in Datas Sources page) for latest/required years.
Parquet vs Iceberg – When to use what?
| Format | Use Case |
|---|---|
| Parquet | Efficient analytics, low overhead, and time travel support with incremental append and dedupe. |
| Iceberg | Required when upsert feature is needed for incremental merge and Full Refresh Merge sync modes. |
Usage of Parquet or Iceberg depends on the actual use case.
Playground
How are custom transformations implemented in DataGOL?
Using the Playground, users write SQL (Spark SQL dialect) to clean, join, and transform data.
Key Points:
- The Playground acts as the editor to perform transformations (like data type changes) in Spark SQL.
- Queries can be saved as views and then published to the workspace as workbooks.
Schema changes
What happens if the schema changes downstream?
Impact Areas: Workbooks and dashboards may break.
Solution: Use the Impact Analysis feature to identify affected widgets, views, and dashboards. Use Playground to test the query and update the workbook schema.
Workspaces and Workbooks
What is the role of the Workbook in the BI flow?
Workbooks are views created from Playground and act as the golden layer for the dashboard. Make sure to update the column datatypes in workbooks since the same datatypes will be inferred in BI. For example, for a date field that must have the date datatype in the workbook, a column that has distinct values can be made a single select type, etc. Keep the workbook columns self-descriptive, which can later help AI answer your questions based on your workbook. Use descriptive workbook names and versioning for long-term maintainability. Use delete protection on finalized workbooks to avoid accidental deletions. Ensure a well-defined, clean structure of workbooks for better BI compatibility.
Key Points:
- Can be published to workspaces.
- Supports API-accessible data, which can be filtered and downloaded.
How is access and sharing managed across workspace?
Workspaces support role-based sharing:
- Creator: Full control.
- Editor: Edit access but cannot delete.
- Viewer/Guest: Read-only; guest can't download data.
Key Points:
- Workbooks and dashboards adhere to these roles.
- Delete protection available at workbook levels. When enabled, it makes the workspace delete protected.
Can workbook data be accessed via API?
Yes, via a CURL command using service accounts.
Key Points:
- Data is returned in paginated JSON.
- Default rows: 0–500 (configurable).
Can users import external data into workbooks?
Yes, via Excel or CSV import.
Key Points:
- Supports creating a new workbook as well as Excel/CSV imports.
- Ensure well defined, clean structure of workbooks for better BI compatibility.
Can filters be propagated across widgets or pages?
Yes, but linking filters across visuals (like dynamic filters) is not yet supported.
Key Points:
- Page-level filters can be configured to include/exclude widgets.
- Column-based linking across workbooks is supported via BI query joins.
How are dashboards created and managed?
Users drag and drop fields from loaded workbooks, configure visual properties, and pin to dashboards. Also refer:
Key Points:
- No widget limits per dashboard.
- Widgets can be duplicated, sorted, and grouped.
- Export to PDF is not yet supported, but on the roadmap.
Was this helpful?