v1.0.158
Date released: August 18, 2025
New features and enhancements
The following new features and enhancements are in this release:
Pipelines: Cluster configurations
The new cluster configuration feature provides a multi-level system for managing the compute resources used by data pipelines and other workloads. This allows for precise control over resource allocation to help optimize for both performance and cost.
How does it work?
The system applies a configuration hierarchy to determine the resources for each job. Specific configurations take precedence over more general ones:
-
Pipeline-level override: You can now set specific configurations for individual pipelines, which will override any company-level or default settings. This is ideal for fine-tuning performance on critical jobs.
-
Company-level defaults: A new company-specific configuration can be set to provide a custom default for all pipelines within your organization. This is useful for standardizing resource allocation and ensuring consistency.
-
Parent pipeline inheritance: For orchestrated jobs, child pipelines without a specific configuration will now inherit the settings from their parent pipeline, streamlining complex workflows.
-
Dedicated node groups: For pipelines requiring specific hardware, you can now select dedicated node groups (e.g., 'Medium', 'Large') and define the number of executors for guaranteed resource allocation.
-
Cache handling: The system now intelligently handles configuration updates, ensuring new pipeline runs use the latest settings after a cache refresh. Existing pipelines will continue to use their original snapshot configuration, preventing unexpected changes to in-flight jobs.
-
Job-specific metadata: All configuration details, including overrides, are now stored in the job metadata, providing full transparency and traceability for every run.
-
Specialized workloads: The system now recognizes and applies specific configurations for various workloads, including Playground queries, Workbook/BI queries, and ETL jobs, to ensure each runs with the most suitable resources.
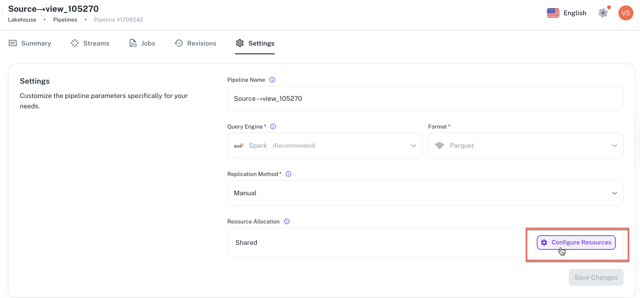
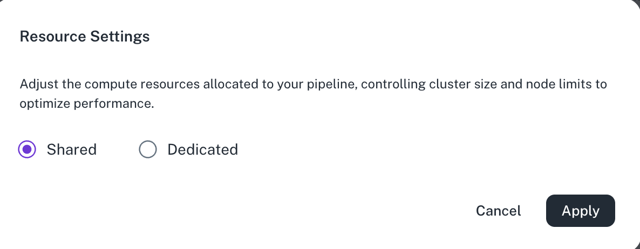
Pipelines: Node group scaling UI
You can now gain granular control over the compute resources allocated to your pipelines. A new UI section is introduced for the pipeline configuration screen that allows you to directly define the cluster size and scaling options for your jobs.
This new feature gives you the flexibility to:
-
Select cluster size. You can now choose from predefined cluster types (e.g., small, medium, large) to match your pipeline's specific performance requirements.
-
Set node scaling. You can define the minimum and maximum number of nodes for a job. This allows you to guarantee a baseline of resources for consistent performance while also enabling cost-effective auto-scaling for variable workloads.
These configurations are stored at the pipeline level, giving you precise control over each of your jobs.
Bug Fixes
This release contains the following bug fixes:
Workspace
The issue causing workbooks to fail when published with the Spark provider and the No Copy option has been fixed. A backend update now ensures these workbooks are created successfully, with all functions—formulas, sorting, and filtering—working correctly.
Was this helpful?