v1.0.160
Date released: August 21, 2025
New features and enhancements
The following new features and enhancements are in this release:
Pipelines
The following enhancements have been made for Pipelines:
-
Unified pipeline view: The pipeline view has been streamlined by removing the concept of parent/child pipelines. Now, everything (status, error logs, and more) is available directly from a single, unified Pipeline page, making it easier to manage and monitor data streams.
-
Pipeline-level actions: To simplify execution and ensure consistency, the ability to run or cancel individual streams has been removed. Users now manage the entire pipeline as a single unit, which helps prevent fragmented runs and ensures that all active streams are processed together.
-
Last sync column: A new column has been added to the Streams tab to show the last time each stream is completed. This gives a quick and clear overview of the most recent activity for each stream, helping to identify which ones might be out of date.
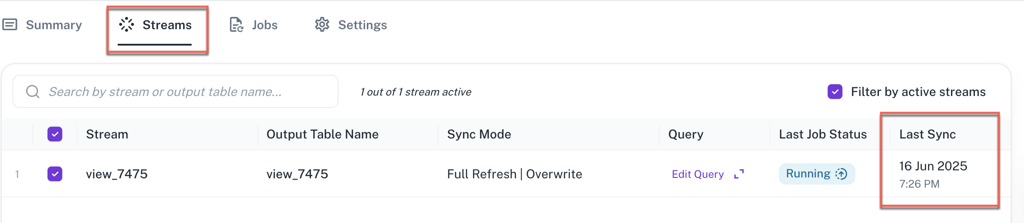
-
Revamped job table: The Job Table has been redesigned to provide more clarity. Each job can now be expanded to see a comprehensive list of all streams that were included in that run, along with their individual statuses. This gives a complete, at-a-glance overview of the pipeline's activity.
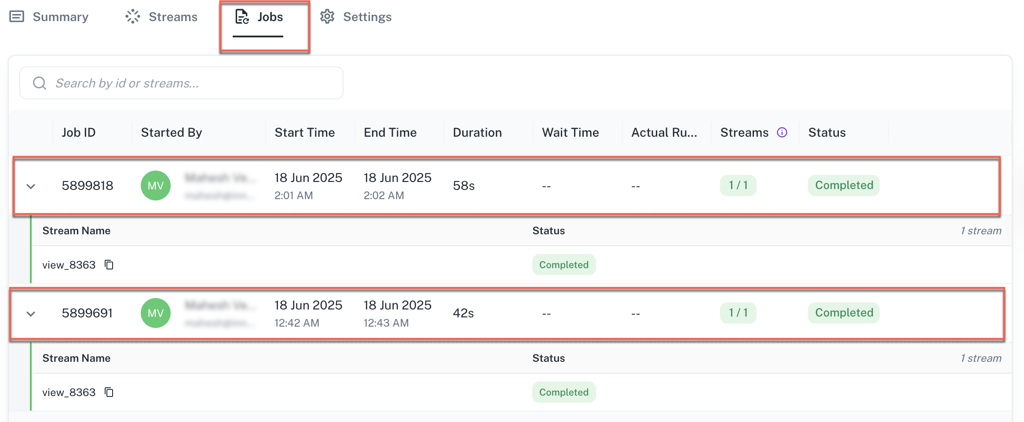
-
"Fix Error" button in the Job table: For custom and deduplication pipeline streams, a new "Fix Error" button is available in the expanded Job Table. This allows users to edit and save queries for failed streams directly from the job view, so issues can be resolved quickly without leaving the page.
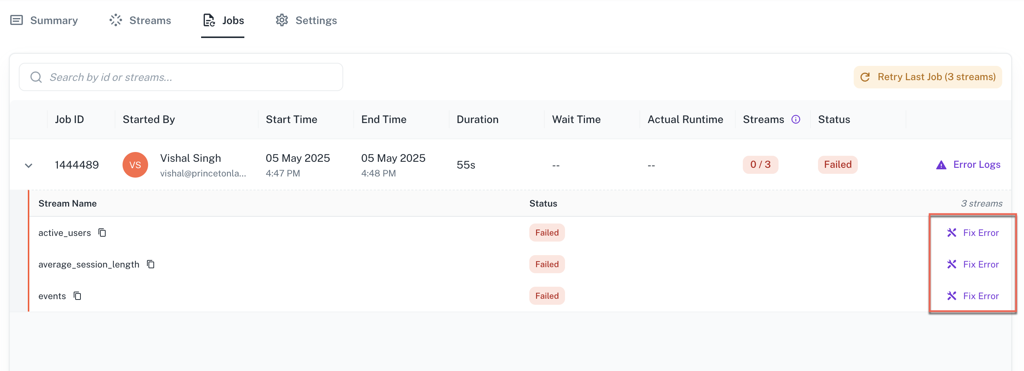
-
Retry Last Job button: You can now retry a failed or canceled job with a single click. The new Retry Last Job button will automatically rerun all streams that were active in the last job, helping to get back on track faster.
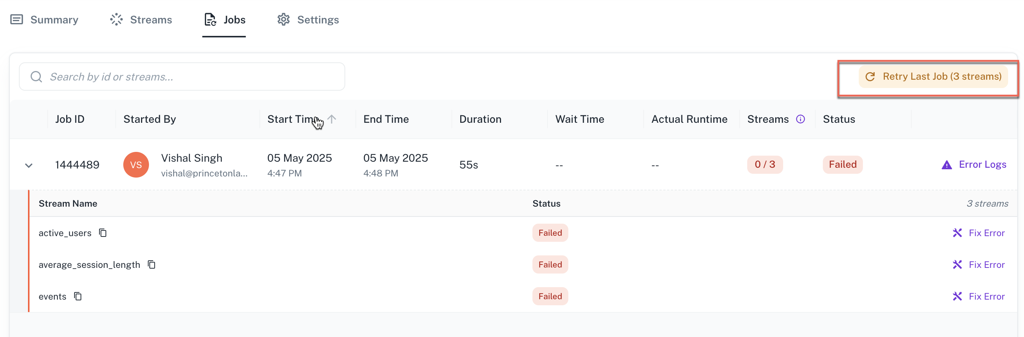
AI
-
Unstructured pipeline metadata enhancement for RAG agent: The unstructured pipelines have been enriched with the following new metadata for each chunk:
-
File ID: A unique identifier for the source document, ensuring direct traceability.
-
Document Title: The original title of the source document, providing immediate context.
-
Reference Link: A direct link back to the source document, allowing for easy navigation and verification.
-
This improvement provides a more robust and context-aware retrieval process, enabling better traceability and seamless navigation to the source files.
BI
Enhanced chart classification: The BI Agent’s chart classification logic has been refined to better interpret user queries. This improvement results in charts that are more accurate, relevant, and aligned with both user intent and the available data.
Backend
-
JDBC provider exception shown with user-friendly error messages: Joining multiple data sources is not supported with the JDBC provider. When a user attempts this, an exception is now handled to display a user-friendly error message instead of a technical one.
-
Table response now returns S3 URL: For tables with an associated pipeline, the table response now includes an S3 URL.
-
Improved dynamic workbook joining: Dynamic workbook joining has been improved to better handle changes in parent workbooks. Renaming a column in a parent workbook will no longer break the joined workbook. Additionally, deleting a column that is not used in the final output will not cause the joined workbook to fail.
The following are known limitations:
-
Renaming columns that are part of the join condition will still cause the resultant workbook to break.
-
Deleting columns that are part of the join condition or final projection will also break the resultant workbook.
The Impact Analysis feature is updated to accurately highlight the changes that will affect the joined workbook before you make them, which helps you manage these limitations.
Was this helpful?