v1.0.183
Date released: October 9, 2025
New features and enhancements
The following new features are included in this release:
Documents
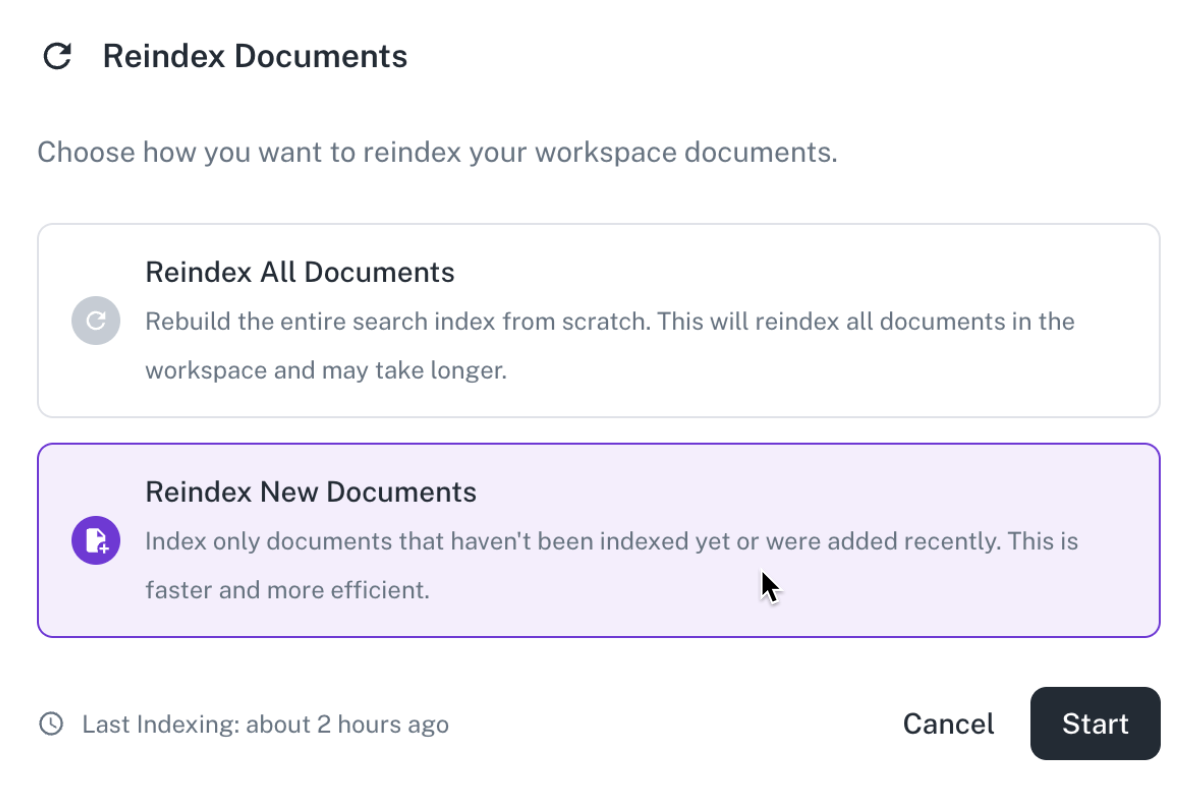
Document re-indexing option: A new option has been added to the Documents user interface, allowing users to trigger re-indexing for a workspace manually. This feature enables users to refresh the search and index state on demand. Users may choose between an incremental re-index, which processes only new or changed items, or a full re-build, which clears the existing index and re-ingests all documents.
Workbook
-
Workbook link validation: Backend validation has been implemented to prevent users from adding multiple links that point to the same workbook. This validation ensures data integrity.
-
Improvement to data fetching for JDBC workbooks: Efficiency has been improved for retrieving schema details in no-copy workbooks by optimizing data fetching for workbooks. Previously, the system queried the entire dataset, which led to high backend load and sometimes caused publishing failures due to resource exhaustion.
The system now includes a row limit of one in the query used to fetch schema information. This change processes only a minimal subset of data to infer the schema, significantly improving backend performance and enhancing the reliability of workbook publication.
Workspace
This release includes several improvements focusing on document handling, search experience, and RAG (Retrieval-Augmented Generation) accuracy:
-
Enhanced workspace document search: The document search experience within the workspace has been improved to align with the global workspace search behavior. You will now see faster and more relevant results when searching for documents, making content easier to discover.
-
Excel file upload re-enabled: Users can now successfully upload Excel files again through the user interface. Once uploaded, users can leverage the AI agent to ask questions based on their Excel data.
-
RAG extraction column mapping fix: Fixed an issue that caused incorrect column mapping during the RAG extraction process. This ensures accurate data alignment between the extracted information and the original document structure, leading to higher-quality AI responses.
Bug fixes
The following bug fixes are included in this release:
Lakehouse
Fixed a display issue on the Lakehouse Jobs page. Users attempting to view the next page of running or failed jobs would previously receive an empty list of records. This was due to the user interface requesting an incorrect page number from the service. Pagination now functions correctly, and all available job records load as expected when navigating between pages.
Orchestration
Fixed a user interface issue where the orchestration payload was not being transmitted correctly whenever an orchestration was scheduled via a cron job. This fix ensures that orchestrations scheduled with cron are updated properly.
Pipeline
Corrected an issue within the unstructured pipeline, where the displayed document chunk count was inaccurate. The chunk count is now calculated and displayed properly.
Was this helpful?